OrionX,助力高效AI实训平台
人工智能大背景
当今世界无时无刻不在发生着变化。对于技术领域而言,人工智能的迅速发展已经在深刻改变人类社会生活、改变世界。经过60多年的演进,特别是在移动互联网、大数据、超级计算、传感网、脑科学等新理论新技术以及经济社会发展强烈需求的共同驱动下,人工智能加速发展,进入新阶段,呈现出深度学习、跨界融合、人机协同、群智开放、自主操控等新特征。未来,人工智能将会成为国际竞争新焦点,国家已经加紧出台政策,围绕核心技术,标准规范,人才培养等方面加强部署。
高校AI实训平台建设
在AI人才培养方面,我国智能科学技术本科教育的开端,可以追溯到2003年北京大学智能科学与技术专业的建立。2012年9月,在教育部公布的新修订《普通高等学校本科专业目录》中,将“智能科学与技术”专业成为“特设”专业,归入计算机类。
十几年间,每年新设智能科学与技术专业的院校数都为个位数,但在最近两年迎来了大幅增长。2019年35所大学新增“人工智能”专业,标志着人工智能本科专业的诞生。2020年180所高校新增人工智能专业,相比2019增加的35所有大幅增加。此外,“双一流”高校人工智能研究生将扩招,AI为王的时代已然到来。
面对热火朝天的“人工智能”专业,高校需要一套全新的AI实训教学平台,具备真实业务场景,具备真实数据,具备真正软硬件环境,帮助构建高校人才培养环境。
其中,在构建真实软硬件环境方面,目前高校主要以数据中心服务器+GPU方式构建,该方式足矣构建强大的“人工智能”算力平台。但是在算力分配与调度方面,目前主要采用K8S+物理GPU方式调度,颗粒度较大,存在以下问题待优化:
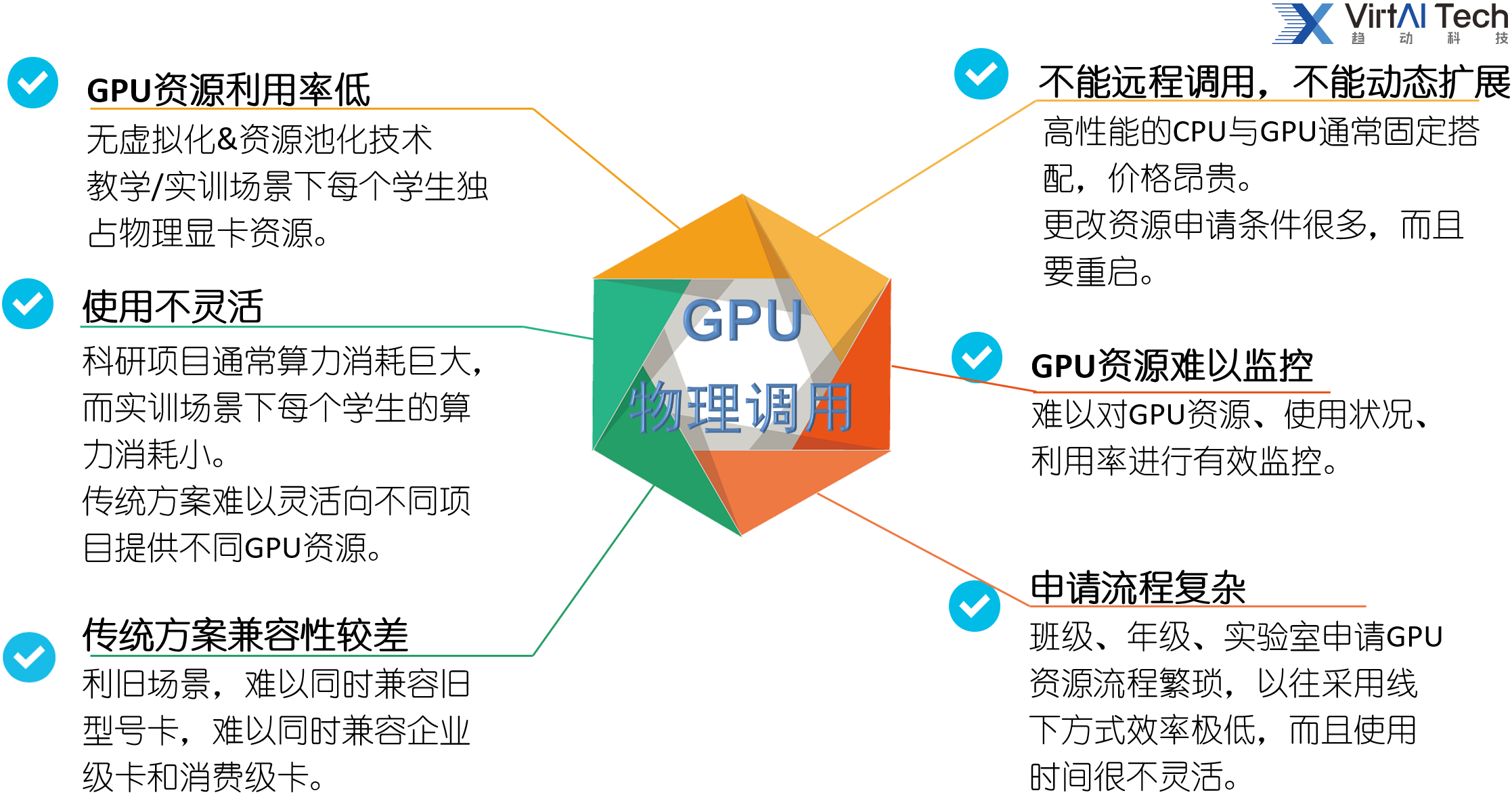
建议的解决方案
使用高性能GPU服务器,搭配趋动科技OrionX GPU资源池化软件,实现基于K8S平台的GPU细颗粒度切分与调度方案。
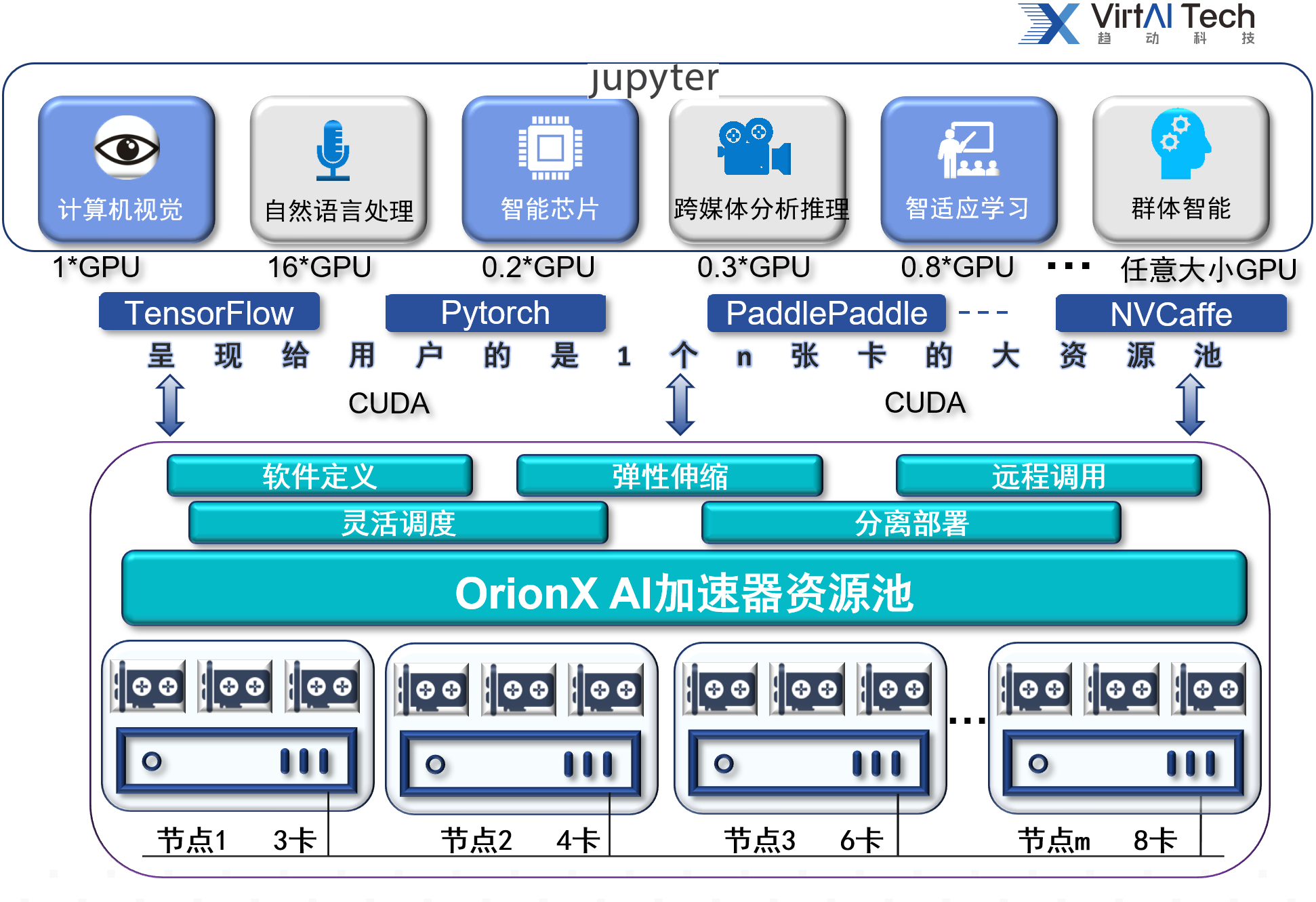
① 支持原生K8S,支持原生容器。与K8S原生调度方案完全兼容,实现弹性,轻量化部署。
② 在教学场景下,实现对物理GPU进行任意颗粒度切分,支持显存隔离,支持算力隔离。切分后的虚拟GPU分配给不同容器,相互之间不影响,确保QoS。
③ 在科研场景下,实现GPU跨机聚合,实现多机多卡聚合成单机多卡,用于大型单机训练任务。
④ 底层虚拟GPU资源对上层应用透明,用户无需改变原有使用习惯,GPU资源申请后立即到位,用完后立即释放。
⑤ 管理员可以集中统一管理,实时监控。
解决方案详解
本方案借助原生K8S容器云为高校构建AI实训软硬件平台。学生用户采用Jupyter Notebook自助申请资源,动态分配与灵活调度,满足学生用户人手一个真实实验环境的需求。
原生K8S可以调度虚拟化的CPU,内存,存储,I/O等资源。
GPU虚拟化由OrionX软件配合K8S实现。OrionX可以对物理GPU进行细颗粒度切分,从显存、算力两个维度实现切分。显存颗粒度细化到1MB,算力颗粒度细化到每个GPU卡1%算力。切分之后的虚拟GPU实现完全隔离,互不干扰。
不同于其他开源方案通过从业务层面对资源大小进行辅助控制,我们是基于底层技术的控制,作用于CUDA以及更加底层的位置,通过开放的API调用方式,直接作用于GPU的驱动层面。因此可以做到跟更精细,隔离性更好。具体逻辑架构、软件构成,工作原理如下:
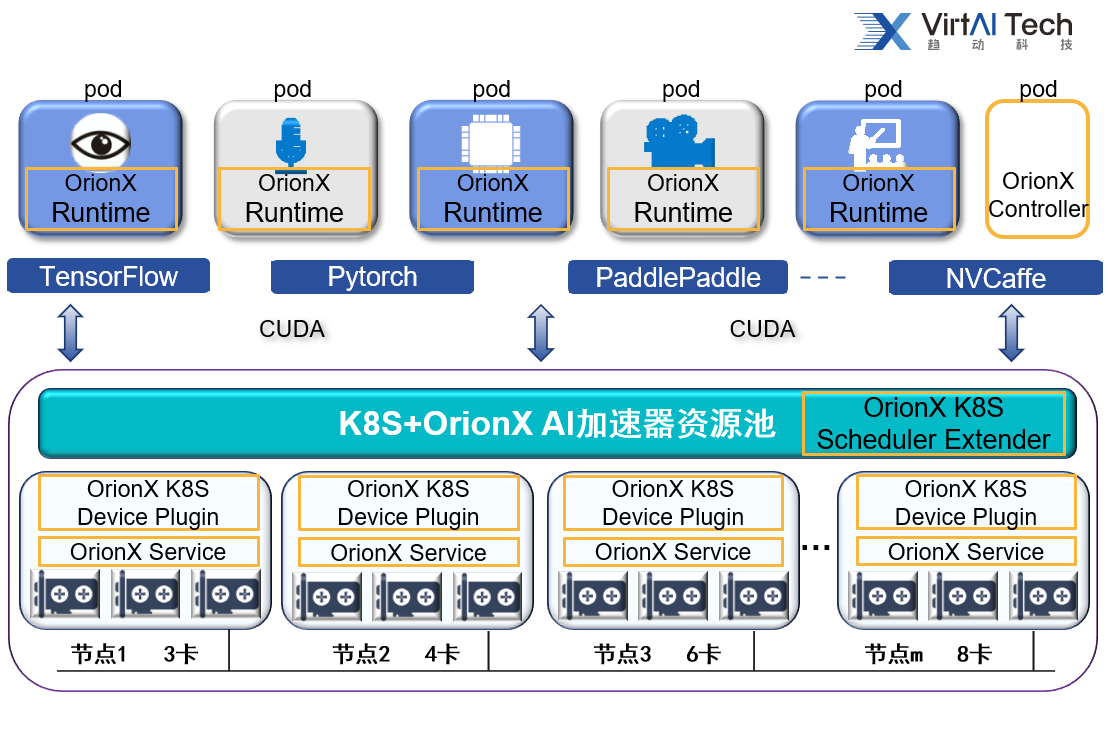
IaaS层:在每个GPU服务器(Worker Node)安装2个组件:
OrionX Service:该组件为一个长运行的系统服务,其负责GPU资源化的后端服务程序。OrionX Service部署在每一个CPU以及GPU节点上,接管本机内的所有物理GPU。OrionX Service为其应用程序的所有CUDA调用提供一个隔离的运行环境以及真实GPU硬件算力。
OrionX Kubernetes Device Plugin:通过Kubernetes定义的Device Plugin标准向Kubernetes注册名字为“virtaitech.com/gpu”的资源;通过和Orion Controller通讯,获取Orion vGPU资源池信息。
PaaS层:在Master Node安装1个组件:
OrionX Kubernetes Scheduler Extender:提供基于HTTP API通讯的松耦合调度扩展功能,通过配置文件向Kubernetes注册名字为“virtaitech.com/gpu”的资源敏感字,使其指向Orion Kubernetes Scheduler Extender的HTTP服务地址。
应用层:每个pod拉起时,镜像里面集成1个组件:
OrionX Runtime:该组件为一个运行环境,其模拟了NVidia CUDA的运行库环境,为CUDA程序提供了API接口兼容的全新实现。通过和OrionX其他功能组件的配合,为CUDA应用程序虚拟化了一定数量的虚拟GPU(OrionX vGPU)。 使用CUDA动态链接库的CUDA应用程序可以通过操作系统环境设置,使得一个CUDA应用程序在运行时由操作系统负责链接到OrionX Runtime提供的动态链接库上。由于OrionX Runtime模拟了NVidia CUDA运行环境,因此CUDA应用程序可以透明无修改地直接运行在OrionX vGPU之上。
管理组件:
OrionX Controller:该组件为一个长运行的服务程序,其负责整个GPU资源池的资源管理。其响应OrionX Runtime的vGPU请求,并从GPU资源池中为OrionX Runtime的CUDA应用程序分配并返回OrionX vGPU资源。 该组件可以部署在数据中心任何网络可到达的系统当中。每个资源池部署一个该组件即可。
方案优势
更节省:从显存、算力2个维度将物理GPU切片为任意大小的虚拟GPU,供多个学生同时使用,互不干扰,充分利用资源,节约成本。
更高效:通过与原生K8S的结合,实现对整个AI实训平台的整体管理和优化,提高整个AI实训平台 GPU的利用效率,提高教学效率。
更智能:虚拟GPU资源随AI应用启动时分配,随应用程序退出时自动释放。
虚拟GPU资源动态分配和动态释放过程无需重启容器。
更灵活:自助式服务,简化管理,简化运维,师生只需关注自己专业,不用在意底层。
更兼容:支持nvidia旗下Tesla,Quadro全系列所有GPU卡,有效降低 GPU的管理复杂度和成本。


