业务挑战:
中国算力规模尤其是智能算力规模正在高速增长,在政策驱动下人工智能算力需求稳增,算力发展进入快车道。今年全国两会期间,全国人大代表、中国移动浙江公司总经理杨剑宇提交《关于加快推进算力网络创新发展的建议》中提到:“虽然我国算力网络发展已经取得较大进展,但是距离让算力成为像水、电一样的社会级服务仍有差距。要加快我国算力网络创新发展,推动算力网络成为像水、电‘一点接入、即取即用’的社会级服务,夯实数字经济的数智底座。”
随着算力总量的大提升,时空维度的分配不均、异构算力管理困难等都是制约算力资源利用率的主要因素。因此,企业在面对业务对算力不断高速增长的需求和有限的资源之间的矛盾时,关键需要统一标准、实现智能化调度,构建起“算力插座”,解决算力接入、调度、智能化匹配等难题。
方案简介:
得益于近些年发展得如火如荼的云原生技术、尤其是作为云原生技术底座的容器云技术的高速发展和产业化落地,业界发现,将GPU等算力资源容器化、资源池化,可以使算力的管理能力拓展到整个数据中心。作为国内为数不多掌握底层核心技术的容器云产品及解决方案提供商,谐云以深厚的容器云底层核心技术,不断推进Kubernetes相关核心组件的性能提升和场景适应性,在AI应用支撑、云边协同、多云管理等方面做了大量优化,在AI算力分配上与趋动科技GPU池化技术紧密结合,从而实现谐云容器云平台将AI应用和GPU服务器硬件解耦,实现虚拟GPU 资源的动态伸缩和灵活调度,解了对AI、大数据、高性能等计算服务有显著需求的企业的燃眉之急。
方案价值:
资源以用户实际应用需求按百分比分配 AI 加速卡算力,按 MB 分配 AI 加速卡显存。
业务容器可在没有配置 AI 加速卡的服务器上运行,并通过 OrionX 使用远端服务器上的 AI 加速卡资源。
多个业务容器可共享同一 服务器上的 AI 加速卡资源,同时进行训练或推理任务,相互隔离。
分布式多卡模型训练时,可将本地和远端的 AI 加速卡资源进行自动汇聚以满足训练任务对 AI 加速卡资源的需求。
支持资源动态分配,当业务容器启动时,OrionX vGPU 资源不会立即分配给该 Pod,在 Pod 运行期间,只有当 AI 应用开始运行的时候,该部分资源才会被该 Pod 占用,AI 任务结束停止时, 资源即被释放。
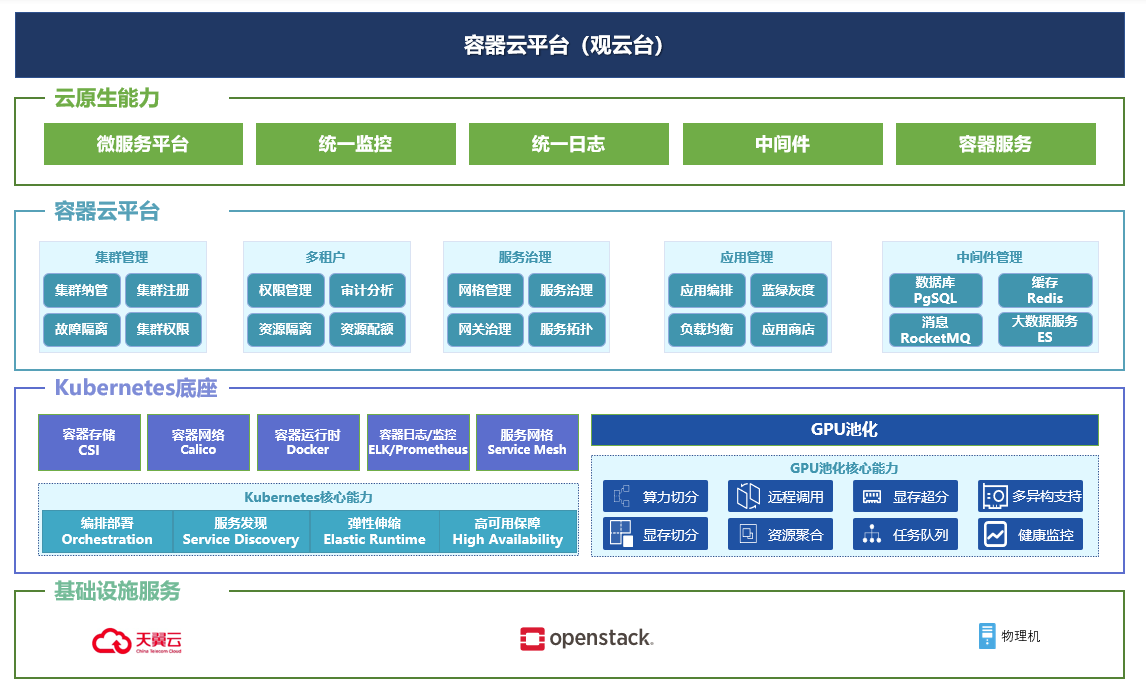
解决方案架构图