中国计算机学会联手体系结构专业委员会发布“GPU池化”术语
开篇导语: 目前,人工智能通过数据、算力、算法和场景的融合深入到各行各业,促进和赋能数智化转型。其中,强大的算力让图像、语音等复杂数据的处理能力得以提升,进而改变传统的人人或人机交互方式,使得新的交互方式迅速得到应用。 现阶段,CPU与GPU搭配的异构计算组合仍然是人工智能算力的首选。在实践中,很多企业AI系统都是通过物理形式直接调用GPU,GPU并没有像云场景中计算、存储、网络虚拟化一样实现资源池化。因此,GPU的利用率极低,导致弹性扩展能力受限,投入产出不成正比。 GPU资源池化技术通过对物理GPU进行软件定义,融合了GPU虚拟化、多卡聚合、远程调用、动态释放等多种能力,解决GPU使用效率低和弹性扩展差的问题。
InfoBox:
中文名:GPU池化
外文名:GPU Pooling
背景与动机:
人工智能的发展对于算力的需求呈指数级增长,其目前速度为每3.5 个月翻一倍(相比之下,摩尔定律是每18个月翻倍)。自2012年以来,全球对于算力的需求增长超过30万倍[8],算力将成为决定人工智能发展上限的重要因素。人工智能芯片是支撑算力的核心部件,当前仍以GPU为主,GPU占据了50%以上的AI算力市场份额[9]。企业级CPU价格在千美元量级,而企业级GPU达到了万美元量级。例如英伟达A100的价格为1万美元左右。因此,在GPU服务器中,GPU的成本能占到整台服务器成本的80%以上。然而,大部分用户的GPU利用率只有10%到30%[10],其核心原因在于,缺乏GPU池化软件使得用户只能基于物理形式直接管理和使用GPU,导致了大量的浪费。
企业内AI项目的建设往往也存在着大量的“烟囱式架构”,例如:有只用于支撑“智能语音”业务的专用硬件和软件平台,也有支撑“智能客服”或“OCR”的专用硬件和软件平台等。这些硬件平台之间往往互相隔离,GPU资源不能被打通进行池化共享导致了GPU利用效率低下。
资源池化是云计算的核心支撑技术之一。资源池的核心是通过软件的方法,将各种硬件(CPU、内存、磁盘、网络等)变成可以动态管理的“资源池”,从而提升资源的利用率,简化系统管理,实现资源整合,让IT对业务的变化更具适应力。GPU池化也是遵循这样的理念,对物理GPU进行抽象,软件化后形成一个统一的资源池,方便用户按需对GPU资源进行有效调用,无需关注实际物理GPU的大小,数量,型号以及安插的物理位置[6]。
GPU池化提供以下几个方面的能力:①GPU物理卡的切分,按算力与显存两个维度,实现1%算力颗粒度,1MB显存颗粒度,以提供与需求相匹配的小于一块物理GPU卡的算力。②远程调用,即在一台CPU服务器上部署AI任务,可以通过网络远程调用GPU资源进行加速,本地无需GPU卡。③资源聚合,把资源池里的多块GPU卡聚合给单个运算任务,让单个任务可以使用更多的GPU卡资源而无需关注单机的GPU数量。④随需应变,按算力需求进行GPU资源的动态扩展,无需重启虚机或容器。
研究概况
学术界和产业界一直在探索如何更优使用GPU资源,不管是伴随服务器虚拟化引入的GPU虚拟化vGPU[3],还是伴随容器兴起引入的GPU资源共享,以及利用CUDA进行API劫持和转发的vCUDA[5],rCUDA[2]。如图1所示,这些技术基本可以归纳为GPU池化发展的四个阶段。
阶段1,简单虚拟化。将单物理GPU按固定比例切分成多个虚拟GPU,比如1/2或1/4,每个虚拟GPU的显存相等,算力轮询。最初是伴随着服务器虚拟化的兴起,解决虚拟机可以共享和使用GPU资源的问题。对于简单虚拟化,2021年英伟达在部分Ampere系列GPU上提供了MIG技术,例如可以将A100切分成最多7份。
阶段2,任意虚拟化。以单物理GPU为目标,支持物理GPU从算力和显存两个维度灵活切分,实现自定义大小(通常算力最小颗粒度1%,显存最小颗粒度1MB),满足AI应用差异化需求。切分后的小颗粒度GPU卡可以满足虚拟机,容器的使用。
阶段3,远程调用。重要技术突破在于支持GPU的跨节点调用,AI应用可以部署到数据中心的任意位置,不管所在的节点上有没有GPU。在该阶段,资源纳管的范围从单个节点扩展到由网络互联起来的整个数据中心,是从GPU虚拟化向GPU资源池化进化的关键一步。
阶段4,资源池化。关键点在于按需调用,动态伸缩,用完释放。借助池化能力,AI应用可以根据负载需求调用任意大小的GPU,甚至可以聚合多个物理节点的GPU;在容器或虚机创建之后,仍然可以调整虚拟GPU的数量和大小;在AI应用停止的时候,立刻释放GPU资源回到整个GPU资源池,以便于资源高效流转,充分利用。
.png)
图1: GPU池化发展的四个阶段
GPU池化技术依赖于第1,第2阶段的GPU虚拟化和第3阶段的GPU远程调用。在此基础上,GPU池化引入控制平面,和之前的数据平面完美契合,形成了如图2所示的软件定义的GPU解决方案(Software Defined GPU)。
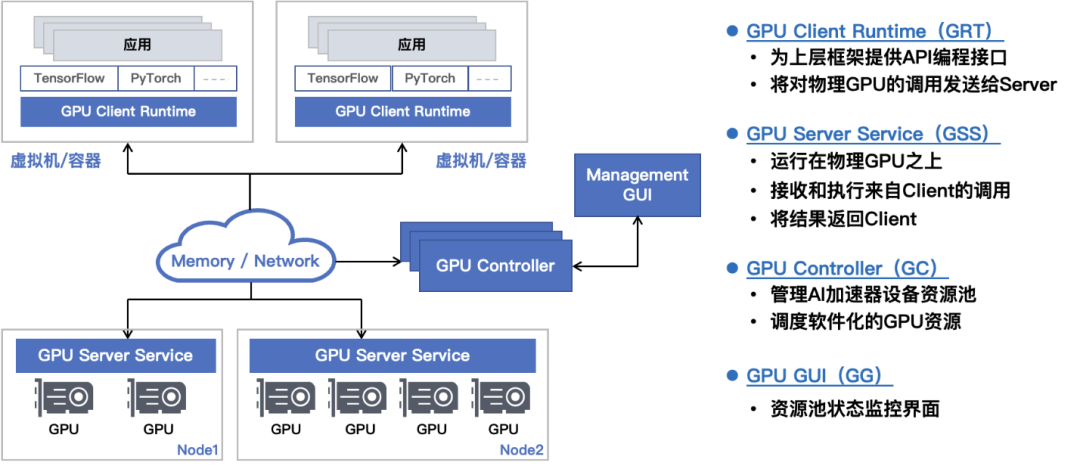
图2: GPU资源池化软件架构图(软件定义的GPU)
GPU池化之后,不仅仅对整个资源池的GPU进行管理和调度,还可以引入很多的高级特性。这些高级特性包括:(1)支持GPU资源的超分,或者超售,这是云厂商希望具备的能力;(2)GPU显存的扩展,可以将CPU的内存用于扩充GPU的物理显存,例如,可以支持CUDA程序在1个只有32G显存的GPU上,分配和使用超过32G显存;(3)在GPU资源不足的情况下,可以对GPU任务进行排队以及队列优先级的设置;(4)在多个GPU任务出现资源争抢时,可以对高优先级任务进行资源保障;(5)支持物理GPU和虚拟GPU的统一管理,按需互相切换等等。除此之外,提供稳定可靠的运行环境,方便的运维,监控,告警,日志,升级功能,也是企业在构建GPU资源池过程中所必须的功能。
未来展望
当前英伟达GPU占据了AI加速器[4]的主要市场,其CUDA软件生态也被大规模地应用。目前市场上,英伟达GPU的池化技术已经有了成熟的解决方案[11], [12],并已在银行,证券,保险,电信运营商,互联网,自动驾驶,教育科研等行业广泛使用。然而,随着AI技术的快速发展,大量新兴的AI加速器应运而生[1]。GPU池化后续应该关注的,不仅仅是英伟达GPU,而是众多新兴AI加速器的池化,即异构加速器的池化[7]。所谓“异构加速器的池化”指的是,资源池可以由多种AI加速器组成,如英伟达GPU,寒武纪MLU,FPGA等,用户的AI应用可以透明地运行在多种AI加速器之上,无需关心底层芯片的类型,同时用户也可以根据自己的需求随意更换资源池中的AI加速器,不会影响上层AI应用的运行。这样用户完全拥有对芯片的自主选择权,可以根据性能、价格、功耗等指标来选择最适合自己的芯片组合。未来异构加速器的池化技术将是企业降本增效,节能减排,弹性支撑AI业务的首选。
参考文献
[1] Albert Reuther,Peter Michaleas,Michael Jones,Vijay Gadepally,Siddharth Samsi,Jeremy Kepner.“AI Accelerator Survey and Trends”, IEEE High Performance Extreme Computing Conference (arxiv 2021).
[2] J. Prades and F. Silla, GPU-Job Migration: the rCUDA Case, Transactions on Parallel and Distributed Systems, vol. 30, no. 12, December 2019[3] Nvidia Virtual GPU (vGPU) software documentation. https://docs.nvidia.com/grid/index.html[4] Adi Fuchs,AI Accelerators — Part IV: The Very Rich Landscape. https://medium.com/@adi.fu7/ai-accelerators-part-iv-the-very-rich-landscape-17481be80917[5] Lin Shi, Hao Chen, Jianhua Sun, and Kenli Li. 2012. vCUDA: GPU-accelerated high-performance computing in virtual machines. Computers, IEEE Transactions on 61, 6 (2012), 804–816.[6] Masahiro Oikawa, Atsushi Kawai, Keigo Nomura, Koichi Yasuoka, Kenichi Yoshikawa, and Tetsu Narumi. 2012. DS-CUDA: a middleware to use many GPUs in the cloud environment. In High Performance Computing, Networking, Storage and Analysis (SCC), 2012 SC Companion:. IEEE, 1207–1214.[7] Giuliano Laccetti, Raffaele Montella, Carlo Palmieri, and Valentina Pelliccia. 2013. The high performance internet of things: using GVirtuS to share high-end GPUs with ARM based cluster computing nodes. In International Conference on Parallel Processing and Applied Mathematics. Springer, 734–744.[8] https://openai.com/blog/ai-and-compute/ [9] https://www.thepaper.cn/newsDetail_forward_11705617 [10] Andy Jassy. 2018. Amazon AWS ReInvent Keynote. https://www.youtube.com/watch?v=ZOIkOnW640A [11] https://blog.csdn.net/csdnnews/article/details/124161968[12] https://www.163.com/dy/article/GQI7K23A0511FQO9.html
作者介绍
王鲲
趋动科技CEO,前Dell EMC中国研究院院长,前微软亚太研发中心高级研究员,前IBM中国研究院高级研究员,主要研究领域为计算机体系结构,虚拟化,分布式系统等。
陈飞 趋动科技CTO,前Dell EMC中国研究院首席科学家,前IBM中国研究院高级研究员,主要研究领域为计算机体系结构,GPU虚拟化,FPGA虚拟化,操作系统等。
邹懋 趋动科技研发SVP,前Dell EMC中国研究院高级研究员,主要研究领域为计算机体系结构,GPU虚拟化,操作系统等。
张增金 趋动科技技术总监,前VMware研发经理,主要研究领域为操作系统,虚拟化等。 李诚 中科大计算机学院特任研究员,CCF高级会员,主要研究领域为分布式系统。


