趋动科技携一体化GPU资源池化解决方案亮相GTC大会
近日,AI行业年度盛会GTC中国线上大会拉开帷幕,来自人工智能和深度学习领域的高科技企业云集线上,在为期5天的大会上共同呈现一场AI科技创新盛宴。北京趋动科技有限公司(以下简称“趋动科技”)作为元脑生态伙伴受邀参加GTC元脑生态技术论坛,发布了基于“浪潮元脑+猎户座(OrionX计算平台)”的一体化GPU资源池化解决方案,获得了广大观众的一致认可和点赞。
深度整合 形成一体化GPU资源池
据IDC研究预测,中国人工智能基础设施市场规模在2020年达到39.3亿美元,同比增长26.8%。人工智能市场的高速增长得益于AI算法的突飞猛进,越来越多的模型训练需要巨量算力支撑才能得到快速、准确的结果,算力已成为未来人工智能发展的决定性因素。

趋动科技技术总监 王亮
趋动科技技术总监王亮在谈到现阶段AI客户面临的普遍痛点时表示:“居高不下的算力成本和有限的算力资源,给AI应用部门与AI基础架构部门带来了诸多挑战,算法工程师与算力资源的配比难题、资源分配不够灵活,额外的运维和调优工作、传统应用架构下GPU资源整体利用率低、无法动态智能支撑上层云环境、资源分散难管理等诸多难题长期困扰着AI用户。
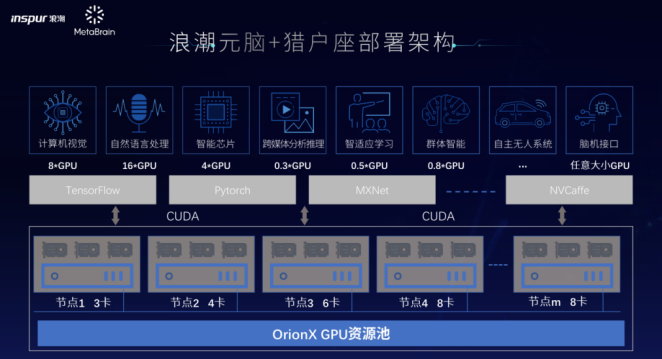
图:“浪潮元脑+猎户座”部署架构
针对上述难题,趋动科技与浪潮联合打造了一体化GPU资源池化解决方案,基于浪潮元脑+猎户座部署架构搭建的GPU云平台,实现了AI应用和物理GPU的解耦。通过OrionX软件层为AI应用提供OrionXvGPU,实现了资源的按需分配,随取随用。解决方案不仅支持推理、训练和教学实训等小模型场景的训练,也支持大模型的训练场景。同时通过支持分布式网络挂载的动态资源调度和回收,使用较少的物理AI加速器资源,即可满足数量庞大的开发人员的AI算力需求。
近日,一体化GPU资源池化解决方案基于浪潮NF5488A5服务器进行了测试。 NF5488A5是浪潮自研的新一代AI服务器,MLperf单项测试性能全球第一。 在4U空间内支持8颗第三代NVLink全互联的NVIDIA A100 GPU,搭载2颗支持PCIe4.0 的AMD EPYC 7742 处理器,NF5488A5能够为AI用户提供5 petaFLOPS的极致单机训练性能和超高数据吞吐,面向图像视频、语音识别、金融分析、智能客服等典型 AI 应用场景。
本次测试采用TensorFlow框架的Benchmark,测试小模型推理,大模型训练等多种AI应用场景,验证平台对A100的兼容性和性能。测试表明,浪潮NF5488A5服务器性能优异,可充分发挥NVIDIA A100 GPU性能,部署OrionXvGPU方案后,本机性能损耗<1%,对比过往服务器的GPU性能,数据提升近50%。
目前,趋动科技的一体化GPU资源池化解决方案已应用于图像识别、语音识别、智能/无人驾驶等场景,带来了显著的客户价值,“我们的解决方案能够帮助客户提高GPU资源利用率;确保与直接使用物理GPU性能无差的高性能;在应用无感知的情况下弹性扩容或者缩容GPU资源池的大小,实现灵活调度;提供外部API接口和上层调度平台、监控平台对接,实现全局管理;简化算法工程师的工作负载,”王亮肯定道。
随需而变 三大场景释放AI算力潜能
“AI算力已经席卷了从服务器到移动处理器在内的几乎所有产品线,同时将AI正式带入场景化、商用化的大规模落地阶段,成为数字社会新基建的关键部分。一体化GUP资源池化方案的问世,通过提高GPU利用率、弹性扩展、按需调度和开放共享的模式,为不同场景构建出了一个AI算力的能源输出与控制中心。”王亮在演讲中指出,“随需而变”是这一解决方案的最明显特征,为AI场景化应用提供了隔空取物、化零为整、化整为零的管理优势。
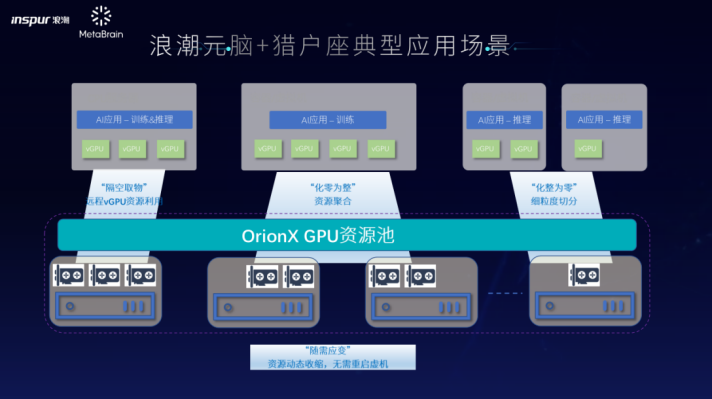
图:“浪潮元脑+猎户座”典型应用场景
n隔空取物:一体化GPU资源池允许AI应用部署在任何一台服务器(纯CPU)上,可根据AI算力资源需求的变化,通过网络去调取GPU服务器上的AI算力资源,从而去支撑训练、推理等灵活应用场景。
n化零为整:用户可以根据需求聚合单设备,甚至多台设备上面的AI算力资源,以容器或者是虚拟机的形式调度,从而支撑多卡的训练,并且通过统一平台管理多源、多场景模型, 实时掌控全局资源 。
n化整为零:工作在本地虚拟化环境下的一体化方案可以轻松实现资源分割、显存分割以及算力的细粒度精准分割,用多卡GPU服务器支撑更多的小模型,如推理、开发环境,教学等场景的需求。
王亮表示:“在智能化需求的推动下,很多AI技术的碎片化应用也开始被广泛使用,几乎所有行业在与AI融合时,都必然要面临算力、平台、应用开发,以及算法、模型训练方面的技术挑战。趋动科技在力争成为业界领先AI应用企业的同时,携手元脑生态合作伙伴,共同推动数据中心级AI加速器资源池化应用,共赢AI时代。”
-实现算力平民化-


