DaoCloud&趋动科技金融行业AI资源池化联合解决方案发布
![]()
金融行业AI概况
伴随着金融科技的不断创新,大数据、人工智能等新兴技术已成为金融行业的重要驱动力,人工智能和大数据正在引发新一轮产能革命,场景营销配套“智能化”服务,金融科技推动数字化转型。
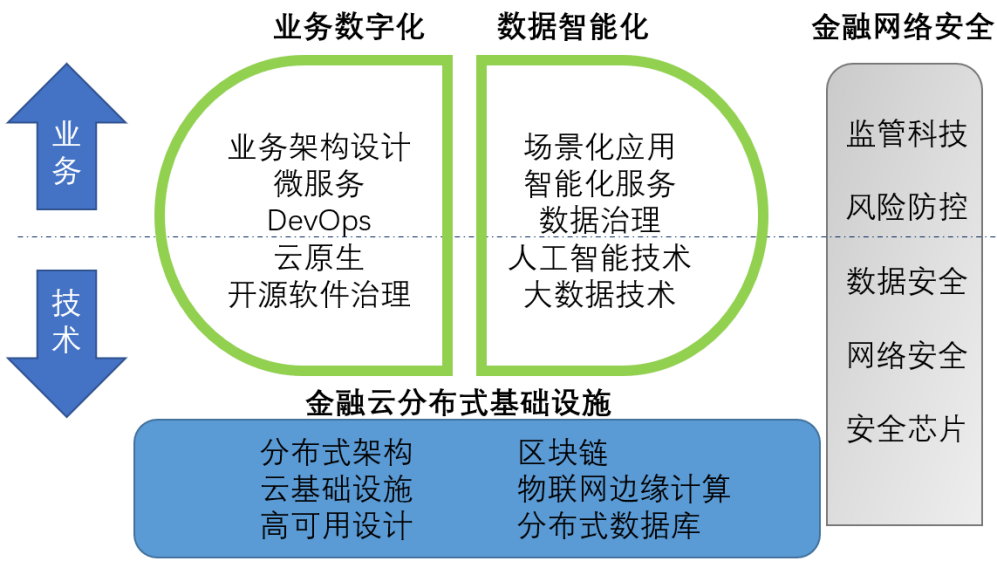
图1:金融科技核心技术组成
数据流动能够产生价值,对于金融行业更是如此。大数据、人工智能等新技术的发展已经推动金融行业从互联网化进入到智能化阶段。AI的出现对于金融行业产生的改变远超想象,大型金融机构都在打造自身的AI能力。

图2:AI技术在金融行业典型应用场景
AI能力构建的痛点
1、AI需要大量试错,哪个框架好?哪个算法好?怎样快速调研模型评估效果?
2、数量众多的算法模型怎么合理管理?
3、数量可观的GPU怎么合理分配给各个开发小组?GPU集群利用率如何提高?
4、新型AI芯片层出不穷,国产化趋势来临,如何对各类异构算力进行管理调度?
AI平台需要为AI的开发部署提供强大且灵活的算力、易用的开发环境以及算法框架的支撑。
解决方案
基于以上问题,各大金融机构都需要构建一个强大易用的 AI级 PaaS平台,直接对接到业务需求,让数据产生价值助力业务快速发展壮大。而相应地,目前越来越多的企业都在基于容器编排调度领域的事实标准Kubernetes来构建自身企业级的PaaS平台,但是在开源生态中,Kubernetes本身在调度 GPU资源方面一直存在诸多限制,比如仅能基于单卡级别进行GPU资源调度,Pod间无法共享 GPU 卡的计算资源,无法实现GPU卡的远程调用的,正是在上述背景情况下,趋动科技与DaoCloud联手,打造并推出了面向 Kubernetes的云原生 GPU资源池化联合解决方案,致力于为企业用户提供面向生产环境的企业级云原生 AI加速器资源池,助力企业在 AI领域的快速发展与持续创新。
趋动科技是人工智能加速器资源池化的领导者,专注于为全球用户提供国际领先的数据中心及AI加速器资源池化和虚拟化软件及解决方案。DaoCloud致力于改变世界创建和交付应用的方式,用技术的力量帮助企业实现数字化转型,致力于成为数字生态领导者和世界一流的企业级PaaS服务商。
在联合解决方案层面,趋动科技基于自身OrionX猎户座计算平台帮助用户构建数据中心级强大的AI加速器资源池,对用户的各类GPU资源进行统一管理、维护、调配。OrionX通过软件定义GPU,颠覆了原有的AI应用直接调用物理GPU的架构,将AI应用与物理GPU解耦。AI应用调用OrionX vGPU(Virtual GPU,虚拟GPU),由OrionX将OrionX vGPU匹配到GPU资源池中的物理GPU,这样,能够达到AI应用透明的共享GPU资源池内的所有GPU资源的目的。该技术既可以实现物理GPU的细粒度切分,也可以实现多机多卡物理GPU的聚合,其灵活与强大程度远远高于一般意义上的单卡GPU共享。
DaoCloud 拥有自主知识产权的核心技术,以云原生为底座构建数字化操作系统为实体经济赋能,推动传统企业完成数字化转型,成立迄今在金融科技多个领域持续深耕,已经有了交通银行、浦发银行、华夏银行等诸多金融领域的标杆客户,凭借自身在云原生领域的多年不懈的持续投入和技术沉淀以及对用户需求的精准对接和深入理解,结合趋动科技的 AI加速器资源池方案,重塑企业云原生企业级 PaaS平台的 AI研发、交付的体系,为客户量身定制AI应用的现代化交付方式。
在AI框架方面,DaoCloud & 趋动科技云原生AI加速器资源池解决方案支持常用的开源框架,包括TensorFlow、Pytorch、MXnet、NVCaffe等。基于此,金融行业客户可以很方便的开展深度学习的训练、推理,轻松使用分布式进行AI任务,大大简化操作流程。为了解决金融客户的数据安全和隐私问题,还支持用户构建联邦学习系统,基于联邦机制建立数据网络,共享知识。
在AI开发环境方面,DaoCloud & 趋动科技云原生AI加速器资源池解决方案为金融客户构建一个简单易用的AI开发平台,支持快速创建项目隔离、资源隔离的 AI应用环境,同时平台内嵌应用商店、模型商店、数据商店,为客户提供代码-打包-训练-推理AI DevOps全流程。
DaoCloud & 趋动科技云原生AI加速器资源池解决方案整体架构示意图如下:
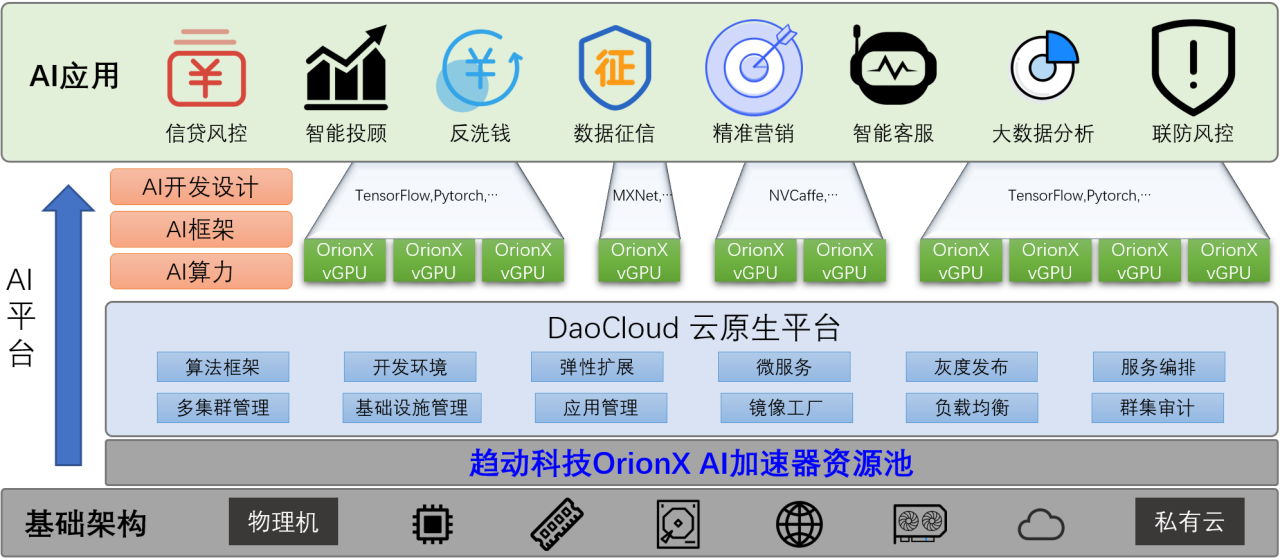
图3:DaoCloud & 趋动科技云原生AI加速器资源池解决方案
OrionX逻辑架构
OrionX的软件逻辑机构如下图所示:
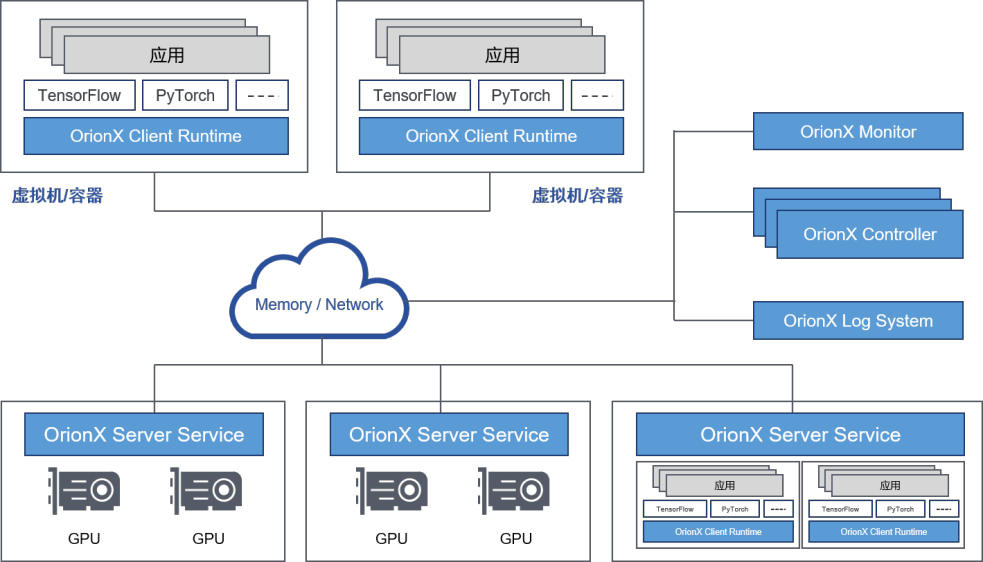
图4:OrionX的软件逻辑架构
各个功能组件的主要功能如下表所示:
功能组件 | 功能 |
OrionXController | GPU资源池的管理、调度模块。负责其他功能组件的服务注册和发现、GPU资源的调度分配等功能 |
OrionXServerService | Ÿ发现并管理本物理节点上的GPU资源 Ÿ把物理GPU资源抽象成OrionXvGPU Ÿ执行AI应用的GPU计算任务 |
OrionXClientRuntime | 兼容Nvidia CUDA编程环境的运行环境,模拟CUDA的运行时接口。自动完成OrionXvGPU资源的申请、释放以及弹性伸缩 |
OrionX Monitor | 提供OrionXvGPU资源池的监控信息 |
OrionX Log System | 负责管理OrionXvGPU资源池的日志 |
DaoCloud & 趋动科技云原生AI加速器资源池应用部署
在 DaoCloud云原生 PaaS平台上支持一键发布 AI应用及对应用进行全生命周期的管理,根据 AI应用的GPU资源配额要求自动完成应用调度及应用GPU资源分配,结合OrionX可实现细颗粒度的GPU资源分配以及远程GPU调用等灵活的应用场景适配。
AI 应用部署示意:
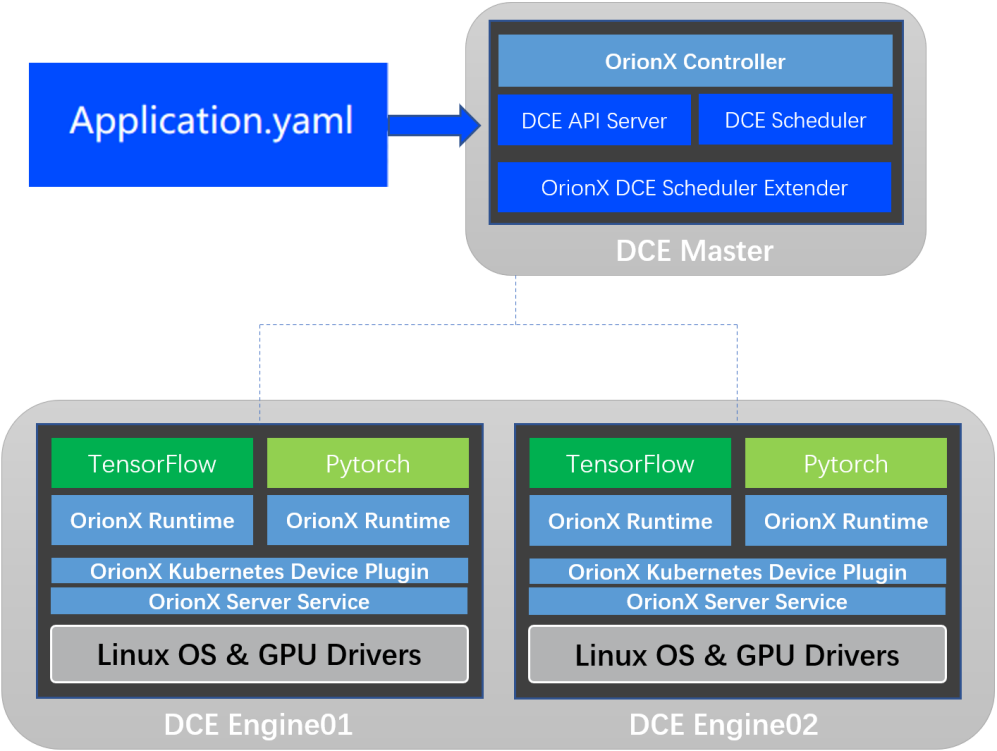
图5:DaoCloud Enterprise(DCE)+ Orion X逻辑架构
相关功能组件说明:
功能组件 | 功能 |
OrionX Kubernetes Device Plugin | 通过和OrionX Controller通讯,获取OrionX vGPU资源池信息 通过Kubernetes定义的Device Plugin标准向Kubernetes注册名字为“virtaitech.com/gpu”的资源 |
OrionX Kubernetes Scheduler Extender | 提供基于HTTP API 通讯的松耦合调度扩展功能 通过配置文件向Kubernetes注册名字为“virtaitech.com/gpu”的资源敏感字,使其指向OrionX Kubernetes Scheduler Extender的HTTP服务地址 |
DaoCloud & 趋动科技云原生AI加速器资源池典型应用场景
DaoCloud & 趋动科技云原生AI加速器资源池支持大模型场景的典型
大模型场景如卡面识别模型训练,智能语音识别训练,声纹识别训练场景,对算力资源需求量大,通常会使用一张或者多张GPU卡资源。作为AI算力资源池平台,DaoCloud & 趋动科技云原生AI加速器资源池 既可以支持单台服务器上的单卡、多卡训练,也可以支持跨设备的多卡训练。
通过“化零为整”功能支持训练
DaoCloud & 趋动科技云原生AI加速器资源池支持将多台服务器上的GPU提供给一个虚拟机或者容器使用,而该虚拟机或者容器内的基于 Horovod 框架的AI应用无需修改代码。通过这个功能,用户可以将多台服务器的GPU 资源聚合后提供给单一虚拟机或者容器使用。 “化零为整”支持训练等大模型场景,为用户的AI应用提供数据中心级的海量算力。
Horovod 是Uber开源的分布式深度学习框架,旨在使分布式深度学习变得快速且易于使用,使模型训练时间从几天和几周缩短到数分钟和数小时。使用 Horovod,可以将现有的训练脚本扩大规模,使其仅用几行Python代码就可以在跨设备的多个GPU上运行。一旦配置了Horovod,就可以使用相同的基础结构来训练具有任何框架的模型,从而随着机器学习技术堆栈的不断发展,轻松地在TensorFlow、PyTorch、MXNet和将来的框架之间进行切换。
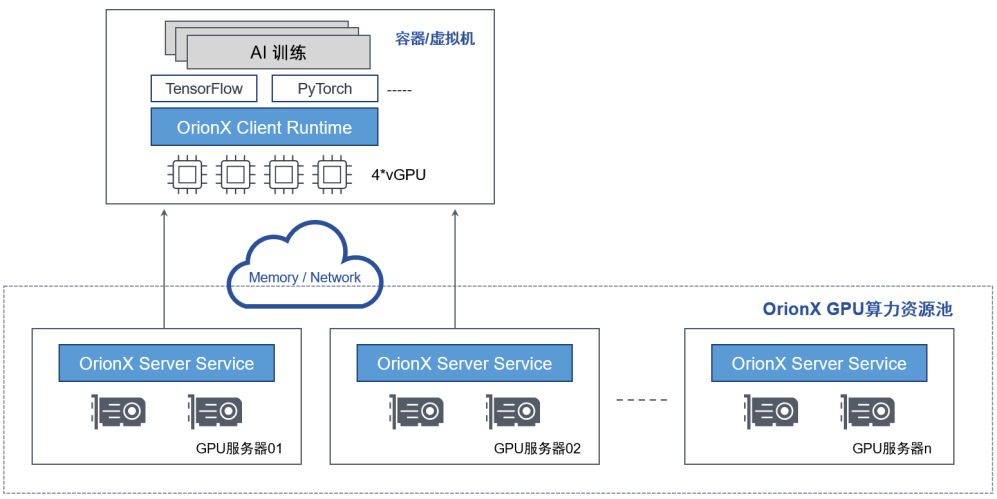
图6-通过通过“化零为整”功能支持训练
通过“隔空取物”功能支持训练
DaoCloud & 趋动科技云原生AI加速器资源池支持将虚拟机或者容器运行在一台没有物理GPU的服务器上,通过计算机网络,透明地使用另一台服务器上的GPU资源,该虚拟机或者容器内的AI应用无需修改代码。通过这个功能,帮助用户实现了数据中心级的 GPU 资源池,实现了 AI 应用和GPU物理资源的解耦合,允许用户的AI应用无障碍地部署到数据中心内的任意服务器之上,并且能够透明地使用任何服务器之上的GPU资源,同时也消除了原有架构中CPU和GPU资源配置固定带来的配比限制问题。
“隔空取物”支持训练等大模型场景,既可以调取单台设备的多卡资源给容器或者虚拟机,实现类似单机多卡训练的场景;也支持调取多台设备的多卡资源给容器或者虚拟机,实现类似分布式多机多卡训练的场景。
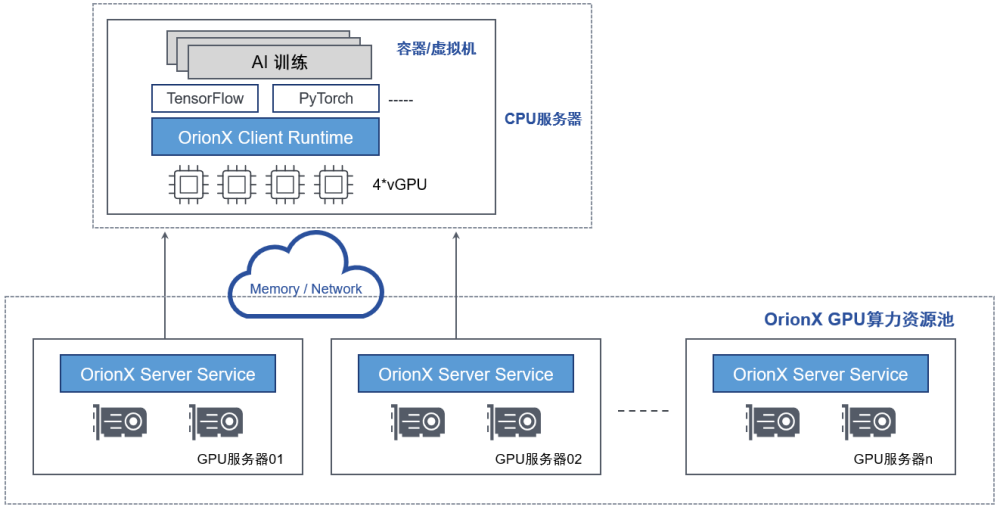
图7:通过“隔空取物”功能支持训练
DaoCloud & 趋动科技云原生AI加速器资源池支持小模型场景的典型应用
小模型如见卡刷卡、智能客服、人脸识别等推理场景,对算力资源需求量小,通常不能占满一张GPU卡资源。作为AI算力资源池平台,DaoCloud & 趋动科技云原生AI加速器资源池可以从算力和显存两个维度,切分GPU。支持将多个小模型任务调度到一张卡,有效提高资源利用率。
通过“化整为零”功能支持推理
DaoCloud & 趋动科技云原生AI加速器资源池支持将一块物理GPU细粒度切分成多块OrionX vGPU,然后分配给多个虚拟机或者容器。每一块OrionX vGPU的显存和算力都能被独立设置和限制。通过这个功能,用户可以高效地共享GPU资源,提高GPU利用率,降低成本。
算力切分的最小颗粒度为原物理GPU算力的 1%;显存切分的最小颗粒度为1MB。
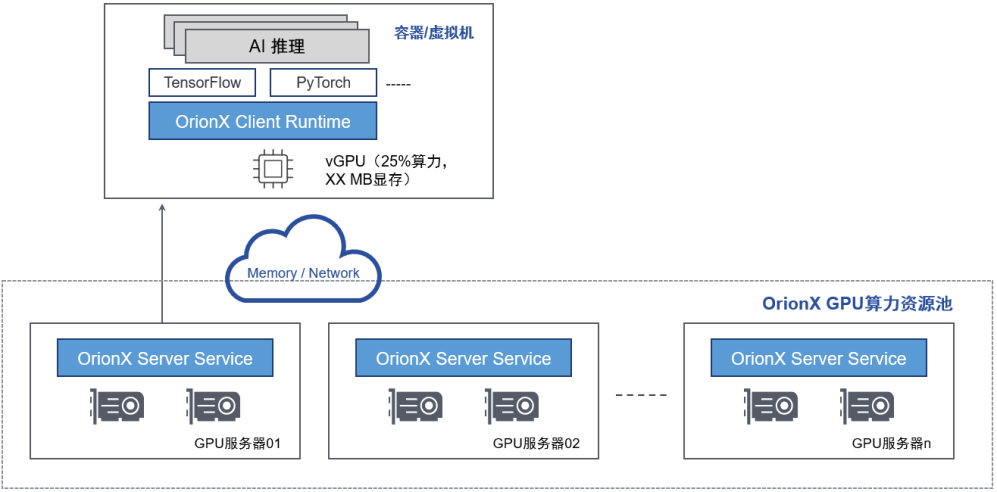
图8-通过化整为零功能支持推理
通过“隔空取物”功能支持推理
“隔空取物”支持推理、开发、教学实训等小模型场景,可以调取单台设备的细粒度卡资源给容器或者虚拟机,将多个小模型应用调用到一张物理GPU 中,并严格限制OrionX vGPU 资源间的隔离,实现资源利用率最大化。
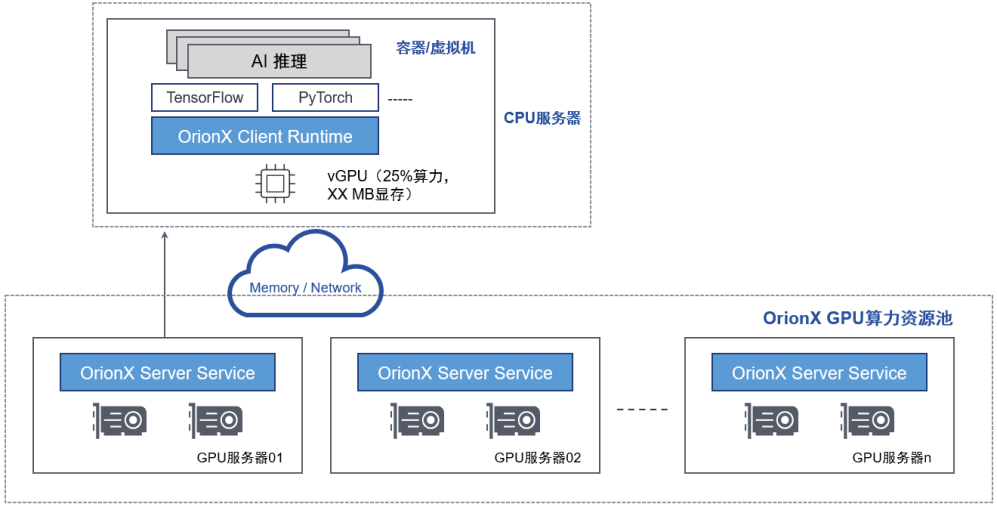
图9:通过“隔空取物“功能支持推理
DaoCloud & 趋动科技云原生AI加速器资源池支持大/小模型场景的典型应用
通过“随需应变”功能支持训练/推理
OrionX 支持用户在虚拟机或者容器的生命周期内,动态分配和释放所需要的GPU资源。通过这个功能,OrionX 帮助用户实现了真正的GPU资源动态伸缩,极大提升了 GPU资源调度的灵活度。
OrionX支持OrionX vGPU资源按需分配、随用随取,最大限度的利用算力资源。不论是大模型训练,还是小模型推理的环境中,用户都可以按照AI模型需求,动态的调整算力资源大小,而无需重启挂载OrionX vGPU的虚拟机/容器。OrionX支持OrionX vGPU资源预留模式和获取模式:
•预留模式:和使用物理GPU类似,客户申请的OrionX vGPU是独占的,不可被其他用户使用。
•获取模式:客户申请的OrionX vGPU是动态的,只有在客户的AI应用运行时,OrionX vGPU资源才锁定到具体的物理GPU,一旦AI应用结束,物理GPU资源及时释放。
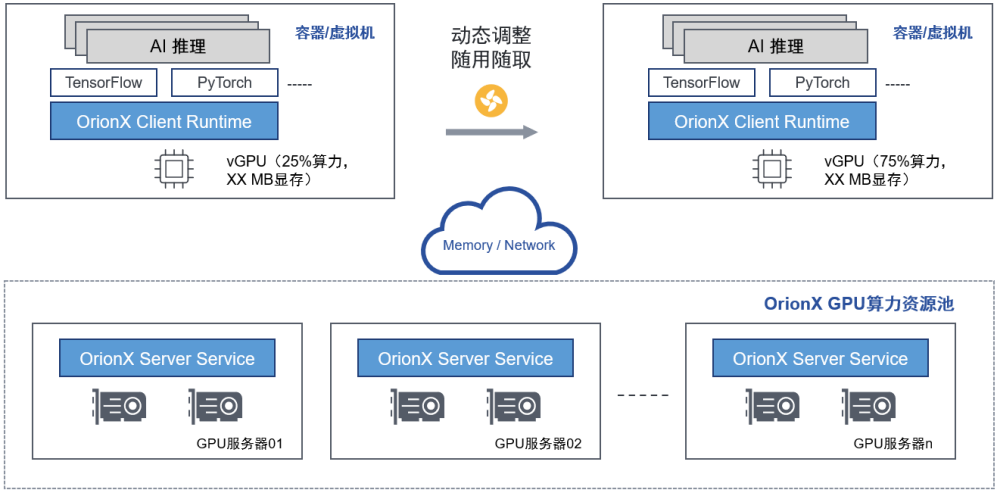
图10-通过“随需应变“功能支持训练/推理
DaoCloud & 趋动科技云原生AI加速器资源池客户收益
1、构建从业务下沉到平台再到基础资源的全栈AI创新能力,AI业务研发人员可以无需关注底层计算、网络及存储等基础设施资源,以业务视角快速定义应用模型并基于平台的AI框架支持能力完成业务的高效发布,形成业务需求到结果反馈的高效AI创新闭环,助力于AI能力的持续创新并最终反哺业务,构建企业级 AIPaaS能力中心。
2、通过软件定义GPU,有助于GPU资源的快速聚合,可以更好的支持模型的快速调研快速试错,有利于金融客户更好地累积业务模型和计量结果,进行全流程风险模型监控,加快模型升级和应用,提升智能化发展速度。
3、统一的AI平台,合理的模型监控与管理,极大降低风控模型升级维护成本,降低重复开发带来的资源浪费和冗余,更好地支持金融产品创新。
4、更加科学合理的资源分配方式,打破原有僵化的GPU资源分配方式,采用按需分配与灵活调度,终结资源排队等待与闲置浪费的矛盾,充分最大化的利用好每一个GPU。
5、支持国产化AI芯片,支持GPU与国产芯片灵活切换,助力金融科技企业更加灵活的选择合适的AI芯片,构建更有优势的算法模型,更精准的了解客户,对业务的判断更加高效,实现普惠金融。
关于DaoCloud
上海道客网络科技有限公司,成立于 2014 年底,公司拥有自主知识产权的核心技术,以云计算、人工智能为底座构建数字化操作系统为实体经济赋能,推动传统企业完成数字化转型。成立迄今,公司已在金融科技、先进制造、智能汽车、零售网点、城市大脑等多个领域深耕,标杆客户包括交通银行、浦发银行、上汽集团、东风汽车、海尔集团、金拱门(麦当劳)等。目前,公司已完成了 C 轮超亿元融资,被誉为科技领域准独角兽企业。公司在北京、武汉、深圳、成都设立多家分公司及合资公司,总员工人数超过 300 人,是上海市高新技术企业、上海市“专精特新”企业和杨浦区 2018 年的“科技小巨人”企业,并入选了科创板培育企业名单。
关于趋动科技
趋动科技于2019年成立于北京中关村高新技术园区,拥有专业的研发、运营和服务团队。趋动科技荣登WISE2020「新基建创业榜」最具成长性创业公司TOP20, 趋动科技的OrionX 猎户座AI算力资源池化解决方案荣获“2020新基建与行业创新应用优秀解决方案” ,“2020智慧高校解决方案卓越奖” 和2020“金麒杯”年度金融行业最佳解决方案服务商。趋动科技致力于帮助客户构建高效的AI算力资源池,提升客户AI运维管理的效率和AI业务应用的效率。根据客户测算,OrionX猎户座软件可以每年提升50%AI算法工程师人效、提升AI资源利用率5-8倍以及让客户总体拥有成本下降80%。
凭借标准化、可复制的产品架构,OrionX猎户座软件得到了包括互联网、金融、电信运营商和高校等大量行业头部客户的认可。
-让计算更简单-


