GPU池化:点燃Jupyter Notebook中的AI算力之火
数据科学的火花在Jupyter Notebook中点燃,而GPU的加入,让这火焰更加炽热!随着人工智能领域的飞速发展,利用GPU加速已成为数据科学和机器学习领域的新常态。
今天,我们要探索的,是Jupyter Notebook与GPU池化技术的美丽邂逅,如何让AI算力发挥到极致!
Kaggle 是一个著名的数据科学和机器学习竞赛平台,由 Anthony Goldbloom 创立于 2010 年。它为数据科学家和机器学习工程师提供了一个分享知识、交流思想、竞赛和合作的环境。Kaggle 已经成为数据科学社区的一个重要组成部分,为数据科学家们提供了一个展示技能、解决复杂问题和相互学习的舞台。
在Kaggle官网的文档里有一篇关于高效使用GPU的技巧和窍门的文章,简单翻译如下(https://www.kaggle.com/docs/efficient-gpu-usage):
Kaggle提供免费访问NVIDIA TESLA P100 GPU。这些GPU对于训练深度学习模型非常有用,尽管它们不会加速大多数其他工作流程(例如,像pandas和scikit-learn这样的库不会从访问GPU中受益)。
您可以每周使用一定限额的GPU。配额每周重置,是30小时,或者根据需求和资源有时更高。
以下是一些帮助您充分利用Kaggle上GPU使用的建议和技巧。通常,对您最有帮助的杠杆将是:
· 仅在您计划使用GPU时才开启它。GPU只有在您使用利用GPU加速库的代码时才有帮助(例如TensorFlow、PyTorch等)。
· 积极监控和管理您的GPU使用情况。
· Kaggle在Notebooks编辑器的设置菜单、kaggle.com/notebooks页面顶部、您的个人资料页面和会话管理窗口中提供了监控GPU使用情况的工具。
· 避免使用批量会话(提交按钮)来保存或检查您的进度。批量会话(提交)从上到下运行所有代码。这比仅从Notebook编辑器下载.ipynb文件效率低。
· 取消不必要的批量会话。
· 如果在完成第一次提交之前按下提交按钮,相同的Notebook可能会有多个并发的批量会话。如果您的最新代码与先前的代码相比已更新,那么最好取消第一次提交,只保留第二次提交运行。
· 在关闭窗口之前停止交互式会话。交互式会话保持活动状态,直到达到60分钟的空闲超时限制。如果在关闭窗口之前停止会话,您可以节省多达60分钟的计算时间。
· 您可以使用屏幕左下角的活动事件窗口来管理您的活动会话,包括停止未使用的交互式会话。在这里了解更多关于活动事件的信息。
· 考虑使用Kaggle-API完全避免交互式会话。有了Kaggle API,您可以在不打开Notebook编辑器中的交互式会话的情况下推送您的笔记本的新版本。
我们希望帮助您充分利用我们的免费GPU计算。祝您Kaggle愉快!
从Kaggle的文章里我们可以看到,其Jupyter Notebook使用GPU资源并没有采用GPU池化技术。所以这些Tips需要用户的特别关照才能更高效地利用自己每周的GPU Quota。
熟悉趋动科技OrionX的同学应该知道,OrionX是一个软件定义的GPU软件,只有当GPU真正使用的时候才占GPU资源,通过这种方式将AI算力效率发挥到最大。
目前国内有不少的客户在Jupyter Notebook这个场景里使用OrionX。
中国AI for Science的头部公司深势科技是一家专注于新一代分子模拟技术的公司,致力于解决微尺度的工业设计难题,其业务方向主要是为药企、材料商和科研机构提供工业研发仿真平台。其推出的Bohrium®科研云平台、Hermite®药物计算设计平台、RiDYMO®难成药靶标研发平台及Piloteye®电池设计自动化平台等微尺度工业设计基础设施,形成了AI for Science的“创新 - 落地”链路和开放生态,赋能千行百业。
深势科技发布的Bohrium®玻尔科研云平台(
https://bohrium.dp.tech/ ),提供海量科研文献数据和领域深度内容沉淀,并通过科学AI助手辅助,帮助用户精准快速地进行科研。让我们来实操一下:
1、通过该平台创建一个Notebook,开始连接,启动Notebook节点。
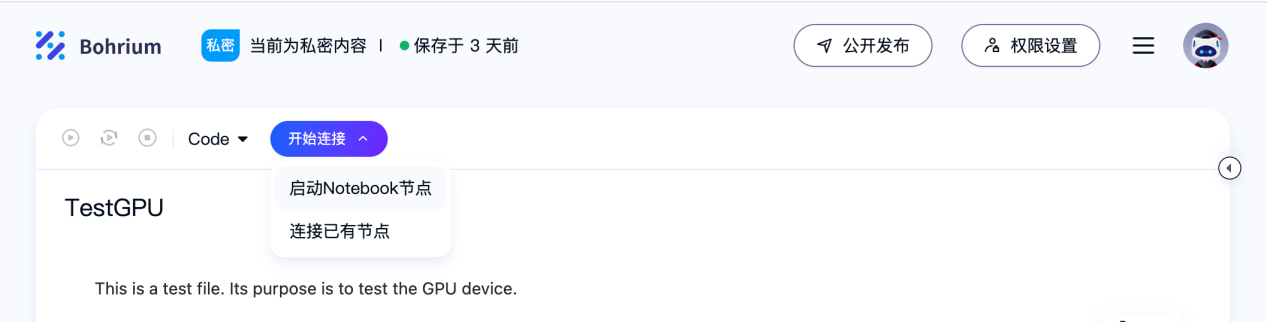
2、弹出对话框后选择镜像和GPU节点,以一个T4、8GB显存的节点为例,可以看到该机型的费用非常便宜,一个小时只需要0.66元。
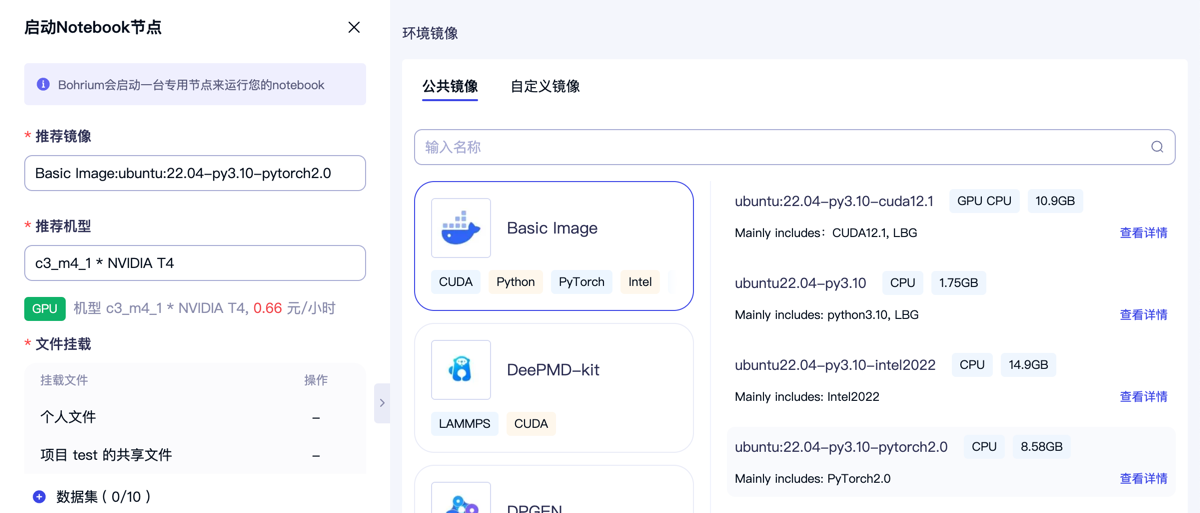
3、点击开始连接,速度还是很快的,几秒钟之后就可以开始编辑和运行Notebook了。简单运行一个torch的cell,发现很快得到矩阵乘的结果:

真的是非常好用,快速地写一段sentimental分析的代码,运行OK。
来自中国移动的九天平台也采用了GPU池化的技术,为更多的用户提供更高性价比的算力服务(https://jiutian.10086.cn/edu/#/home )。
此外,趋动科技推出的趋动云(www.virtaicloud.com)也是OrionX enabled的GPU池化技术。
除了这些对外提供公共服务的平台之外,很多的企业在私有化环境使用GPU池化技术来激活Jupyter Notebook开发场景的AI算力。例如:富国基金、文远知行、清华大学等。
最后提一句,GPU池化和GPU splitting(分割)、GPU sharing(共享)不一样——分割是将GPU容量分割成更小的部分或时间片段,而共享则是将GPU容量汇集起来,允许多个客户端同时访问。
GPU池化是真正的通过软件定义的方式将算力汇集,客户端使用GPU像我们使用水电一样,即取即用,用多少取多少,即关即停,不用关心算力的具体位置。通过这样的方式,将GPU算力发挥到最大,从而实现接近100%的利用率。让我们一起拥抱GPU池化,点燃Jupyter Notebook的AI算力之火!


