用户指南
User Guide
概述
Orion vGPU软件是一个为云或者数据中心内的AI应用,CUDA应用提供GPU资源池化,提供GPU虚拟化能力的系统软件。通过高效的通讯机制,使得AI应用,CUDA应用可以运行在云或者数据中心内任何一个物理机,Container或者VM内而无需挂载物理GPU。同时为这些应用程序提供在GPU资源池中的硬件算力。通过这种Orion GPU池化的能力,可以提供多个优点:
- 兼容已有的AI应用和CUDA应用,使其仍然具有使用GPU加速的性能
- 为AI应用和CUDA应用在云和数据中心的部署提供了很大的灵活度。无需受GPU服务器位置、资源数量的约束。
- Orion GPU资源随AI应用和CUDA应用启动时分配,随应用程序退出时自动释放。减少GPU空闲时间,提高共享GPU的周转率。
- 通过对GPU资源池的管理和优化,提高整个云和数据中心GPU的利用率和吞吐率。
- 通过统一管理GPU,减轻GPU的管理复杂度和成本。
支持列表
处理器
- x86_64
操作系统
- 64位CentOS 6 /7
- 64位 Ubuntu 16 / 18 / 20
NVIDIA GPU
- NVIDIA Tesla 系列:H系列、L系列、A系列、T系列、V系列、P系列、M系列
- NVIDIA GeForce 系列:RTX 30系列、RTX 20系列、GTX 10系列、GTX 98/97/96/95/75系列
- NVIDIA Quadro 系列:RTX系列、GV/GP系列、P系列、M系列
寒武纪 MLU
- MLU-370-X4 / X8
- MLU-270-X5K
中科海光 DCU
- Z100L、Z100
NVIDIA CUDA
- CUDA 12.0,12.1
- CUDA 11.0, 11.1, 11.2, 11.3, 11.4,11.5,11.6,11.7,11.8
- CUDA 10.0, 10.1, 10.2
- CUDA 9.0, 9.1, 9.2
寒武纪 Neuware
- Neuware-3.4.2
- Neuware-3.0.2
- Neuware-2.8.5
- Neuware-2.7.3
- Neuware-2.6.4
- Neuware-2.5.2
中科海光 DTK
- DTK-22.04
深度学习框架
- TensorFlow for CUDA : 1.8 - 2.12
- TensorRT : 5.x / 6.x / 7.0 / 7.1 / 7.2 /8.x
- Pytorch for CUDA : 1.0 - 2.0
- PaddlePaddle: 1.5 / 1.6 / 2.0 / 2.1 / 2.2/ 2.3.2
- ONNX : 1.0 / 1.1 / 1.2 / 1.3 / 1.4 / 1.5 / 1.6 / 1.7 / 1.8 / 1.9 / 1.10 / 1.11/1.12
- MXNet :1.4.1 / 1.6 / 1.7 / 1.8 / 1.9
- XGBoost :0.72、0.8、0.9
- NVCaffe :1.0
- Cambricon Tensorflow for Neuware:1.15 / 2.4
- Cambricon Pytorch for Neuware:1.6 / 1.9
- Cambricon Tensorflow Horovod:0.12.1
- Cambricon Magicmind:0.6
- DTK Tensorflow :1.15/2.7
- DTK PyTorch:1.10
- DTK PaddlePaddle:2.3.0
网络
- TCP/IP以太网络
- RDMA网络(InfiniBand和RoCE)
容器环境
- Docker 12.03及以后版本
虚拟化环境
- QEMU-KVM (QEMU 2.8以上)
容器框架
- Kubernetes 1.10 及以后版本
更多兼容环境未逐一列出,联系我们详细了解
已知问题
下面列出当前版本不支持的CUDA库、工具以及使用模式
- 不支持CUDA应用程序使用 Unified Memory
- 不支持 nvidia-smi 工具
- 有限支持CUDA IPC,对部分程序可能不支持。
必要组件介绍
Orion Controller
该组件为一个长运行的服务程序,其负责整个GPU资源池的资源管理。其响应Orion Client的vGPU请求,并从GPU资源池中为Orion Client端的CUDA应用程序分配并返回Orion vGPU资源。
该组件可以部署在数据中心任何网络可到达的系统当中。每个资源池部署一个该组件。资源池的大小取决于IT管理的需求,可以是整个数据中心的所有GPU作为一个资源池,也可以每个GPU服务器作为一个独立的资源池。
Orion Server
该组件为一个长运行的系统服务,其负责GPU资源化的后端服务程序。Orion Server部署在每一个CPU以及GPU节点上,接管本机内的所有物理GPU。通过和Orion Controller的交互把本机的GPU加入到由Orion Controller管理维护的GPU资源池当中。
当Orion Client端应用程序运行时,通过Orion Controller的资源调度,建立和Orion Server的连接。Orion Server为其应用程序的所有CUDA调用提供一个隔离的运行环境以及真实GPU硬件算力。
Orion Client
该组件为一个运行环境,其模拟了NVidia CUDA的运行库环境,为CUDA程序提供了API接口兼容的全新实现。通过和Orion其他功能组件的配合,为CUDA应用程序虚拟化了一定数量的虚拟GPU(Orion vGPU)。
使用CUDA动态链接库的CUDA应用程序可以通过操作系统环境设置,使得一个CUDA应用程序在运行时由操作系统负责链接到Orion Client提供的动态链接库上。由于Orion Client模拟了NVidia CUDA运行环境,因此CUDA应用程序可以透明无修改地直接运行在Orion vGPU之上。
典型部署架构
以下介绍两种常见的Orion GPU资源池化部署方案。一种是All-in-One的本地GPU虚拟化方案,一种是部署到分布式多台物理机的GPU资源池化方案。
Orion GPU资源池化方案
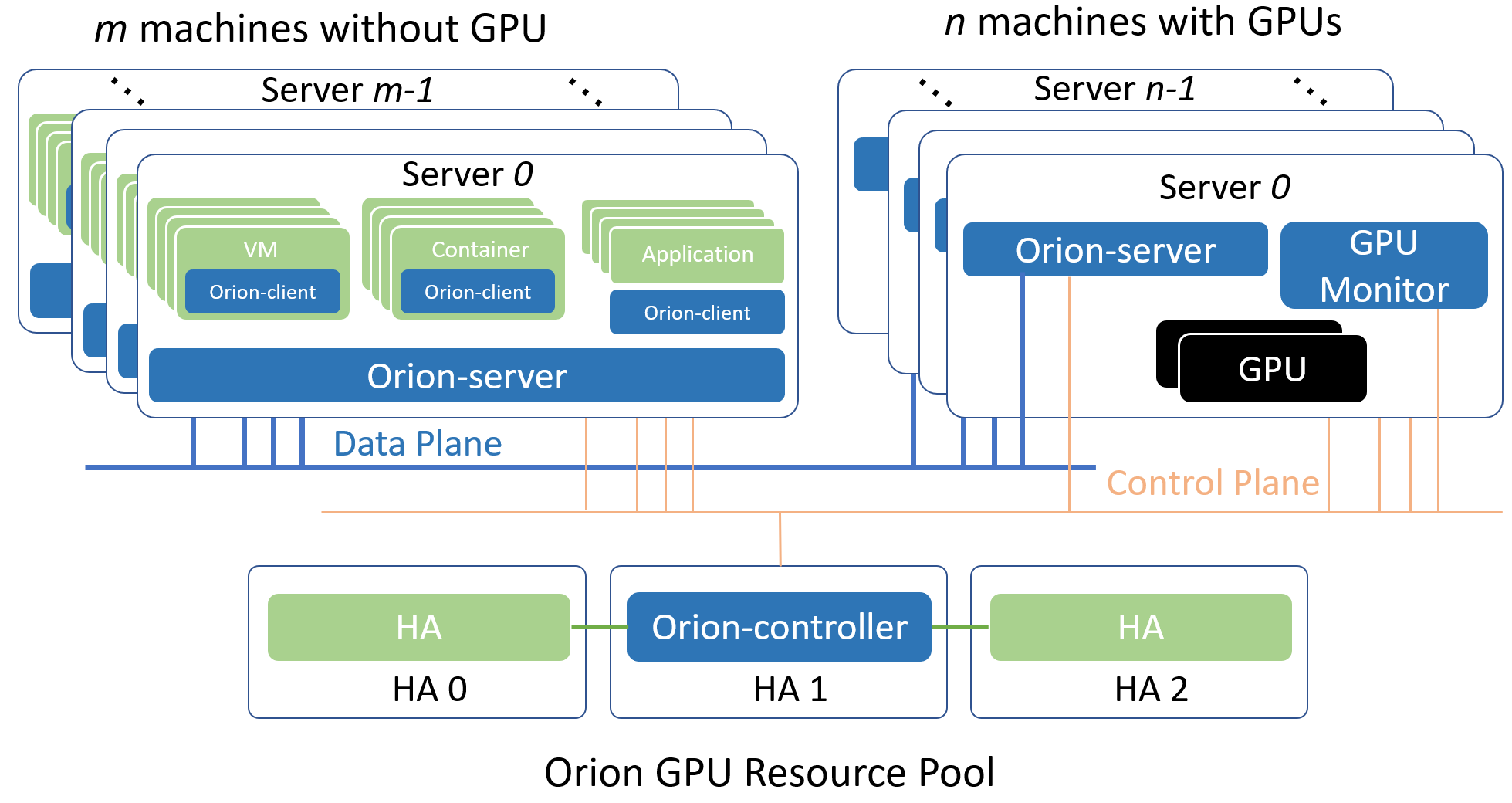
分布式GPU资源池化方案指的是把一台或者多台服务器内的GPU作为资源池,通过Orion向局域网内任一个物理机、Container或者VM内的CUDA应用程序提供虚拟化GPU的部署方式。
选择局域网内至少一个Linux服务器部署Orion Controller。该Controller必须可以被属于同一个资源池的其他Orion组件通过网络访问。
每一个服务器上部署Orion Server服务,Orion Server自动适配该服务器是否安装有GPU,从而开启不同的功能。
在每一个需要运行CUDA应用程序的物理机、Container和VM里部署Orion Client运行库。
各个Orion组件通过Orion Controller的控制功能完成服务发现,资源调度等功能。
从逻辑上,以上各个Orion组件使用了control plane和data plane两套网络。其中control plane用于和Orion Controller组件的通讯。该部分通讯流量不大,对网络延迟和带宽需求不高。data plane用于Orion Client和Orion Server之间执行CUDA任务之间的通讯。该部分对于网络的延迟和带宽有一定需求。建议使用支持RDMA的网络。在实际环境中,control plane和data plane可以是同一个物理网络。
安装部署
以下安装部署的步骤,说明,均以Orion软件包存放路径在 /root/orion 为例进行说明
GPU Monitor
该组件为可选组件,用于监控物理GPU的利用率。如果生产环境中已有其他替代的功能,该组件可以不用部署。
环境依赖
- Docker容器环境
- 与Docker版本匹配的Nvidia Docker runtime
- Nvidia GPU驱动
执行如下命令导入容器镜像,并运行服务
cd /root/orion/gpu-monitor
gunzip dcgm-exporter.tar.gz | docker load
gunzip node-exporter.tar.gz | docker load
./run-nvidia-exportor.sh
Orion Controller
Orion Controller包括物理GPU管理,vGPU资源分配,GUI监控,管理功能。在典型使用场景下,在一个分布式环境,仅需要部署一个实例。以下通过容器化部署Orion Controller。
环境依赖
- Docker容器环境
激活文件下载
用户在部署Orion Controller之前,需确保已经下载激活文件。
如何下载激活文件:
进入趋动科技官网, 注册并登录
进入产品页面点击“申请试用”按钮成为试用用户,或者点击“申请购买”按钮付费购买产品,并等待管理员审核。
经管理员审核后,成功申请试用,或者已经付费购买的用户,可以进入您的个人中心页面,点击“下载激活文件”按钮获取您的激活文件。对于联网环境和非联网环境的用户,需要下载激活文件的方式有所不同,详情请参考“下载激活文件”页面描述。

进入/root/orion/controller目录
cd /root/orion/controller
用您下载到的激活文件license.txt替换/root/orion/controller目录里的已有的license.txt即可。
启动Orion Controller服务
执行如下命令导入容器镜像,并运行服务
cd /root/orion/controller
gunzip orion-controller-ent-2.2.tar.gz | docker load
gunzip prometheus.tar.gz | docker load
编辑配置文件 /root/orion/controller/prometheus.yml
修改static_configs中的targets 列表,该列表是安装了GPU Monitor服务的GPU服务器的列表。当GPU Monitor有多个IP网段地址的时候,该地址应该与 第3章节部署Orion Server时绑定的数据网段相同,例如文档中的“ORION_BIND_ADDR=CCCC”地址,或者是Orion Server的配置文件中的bind_addr相同。
执行如下命令运行Orion Controller服务:
cd /root/orion/controller
./run-controller.sh
服务成功启动后,根据屏幕输出提示,在本宿主机的所有网段提供如下服务:
- 调度服务:部署Orion Server时需要配置该地址
- Web GUI服务:通过浏览器访问该服务进行监控和管理
Orion Controller的日志文件
Orion Controller的日志文件存放在Orion Controller 容器内的 /root/controller.log 中
Orion Server
Orion Server为GPU资源池化提供底层的虚拟GPU服务。在所有的CPU节点、GPU节点均需部署该服务。
Orion Server支持的虚拟化/容器平台有:
- Docker :>= 1.13
- Libvirt + QEMU-KVM : QEMU > 2.0.0
CUDA业务运行KVM虚拟的场景,在把Orion Server部署至宿主机时,由于宿主机可能存在SELinux,apparmor的限制,安装Orion Server之后的配置,仅对安装之后新创建的虚拟机,或者是从Power OFF状态重新启动的虚拟机生效。
环境依赖
对于无物理GPU的CPU节点
- g++ 4.8.5 或以上版本
- Linux基本库依赖libcurl3, libibverbs1, numactl-libs(libnuma), libvirt-devel
- 如果使用Mellanox RDMA网络,需要安装RDMA驱动,以及Mellanox的OFED
GPU节点额外的环境需求
- 安装有Nvidia 物理GPU 驱动
- NVIDIA CUDA SDK 9.0, 9.1, 9.2, 10.0, 10.1
- NVIDIA CUDNN 7.4.2 以上版本,推荐 7.6.x
- NVIDIA NCCL 和最高CUDA SDK版本匹配
在CPU、GPU服务器宿主机执行如下命令安装Orion Server
cd /root/orion/server
sudo ./install-server.sh
配置Orion Server
通过配置文件 /etc/orion/server.conf 可以对Orion Server进行必要的配置,其中支持的配置选项有:
[log]
log_with_time = true ; 记录日志的时候是否添加时间戳
log_to_screen = true ; 日志是否输出到屏幕的标准输出
log_to_file = true ; 是否记录日志至磁盘文件中
log_level = INFO ; 日志级别,支持 INFO, DEBUG
file_log_level = INFO ; 日志输出到文件中的日志级别
[controller]
controller_addr = 127.0.0.1:9123 ; Orion Controller的调度器IP地址和端口
[server]
vgpu_count = 4 ; 默认一个物理GPU被拆分成多少个vGPU
bind_addr = 127.0.0.1 ; data plane的IP地址
;bind_net = ; data plane的网络名字,例如eth0, eth1。bind_addr 和 bind_net 仅能配置1个
listen_port = 9960 ; Orion Server的服务端口
enable_kvm = true ; 是否支持Orion Client运行在KVM的VM中
enable_shm = true ; 是否使用共享内存加速通讯
enable_rdma = true ; 是否使用RDMA加速通讯
ibverbs_device = mlx5_0 ; 如果使用RDMA,硬件设备名。仅在Orion Server无法推断硬件时需要配置
[server-nccl]
comm_id = 127.0.0.1:9970; nvidia NCCL通讯的网络和端口
[throttle]
throttle_level = 100 ; 算力控制的隔离程度,取值范围[0, 100]。数字越少隔离越好
enable_computation_throttle = true ; 是否启动算力控制
computation_throttle_mode2 = true ; 算力控制的模式,仅支持true
Orion Server任务控制
通过如下命令可以启动Orion Server
sudo systemctl start oriond
通过如下命令可以执行其他Orion Server操作
sudo systemctl stop oriond ## 停止Orion Server服务
sudo systemctl restart oriond ## 重启Orion Server服务
sudo systemctl status oriond ## 查看Orion Server服务状态
sudo systemctl enable oriond ## 添加Orion Server服务到开机启动服务
sudo journalctl -u oriond ## 查看Orion Server的服务日志
Orion Server的日志文件
Orion Server的日志存在两个位置
- /var/log/orion/server.log 该文件记录了所有Orion Client的握手过程
- /var/log/orion/session 该目录以单个文件的形式,记录了每次业务运行时的日志。每运行一个Orion Client应用,该目录产生一个独立的日志文件。如果在握手过程中失败,则不产生日志文件。
多版本 CUDA SDK 共存
Orion Server 可以同时支持多个CUDA版本,使得依赖不同CUDA版本的上层应用可以同时使用Orion vGPU。为了支持多个CUDA SDK版本,Orion Server 要求 CUDA 安装在宿主机默认路径(即 /usr/local/cuda-x.y)下面。例如为了支持 CUDA 10.0 和 CUDA 9.0,/usr/local 目录下应该有 cuda-9.0 和 cuda-10.0 这两个目录。
此外,多 CUDA 版本共存时,不需要设置 CUDA_HOME,LD_LIBRARY_PATH 等环境变量,也不依赖于部分用户环境中存在的软链接 /usr/local/cuda => /usr/local/cuda-x.y,这是因为 Orion Server 可以根据 Orion Client 环境中实际安装的 Runtime 对应于 CUDA 的版本号,动态选择合适的 CUDA SDK 版本。
查看Orion 服务状态
在同一个局域网内,通过浏览器(推荐chrome)访问Orion Controller所在环境的局域网地址: http://IP:Port
其中IP为Orion Controller所在环境的局域网地址,Port为部署Orion Controller时提示的Web GUI的服务端口。通过默认用户名(密码 )登录进入系统 : admin(admin)
在侧边栏里看到Orion Controller的IP地址,点击展开之后有如下的内容:
- 摘要:显示Orion Controller所管理的整个Orion vGPU资源池的资源数量,节点状态等
- 任务:显示正在运行且使用了Orion vGPU资源的任务,以及每个任务使用的vGPU资源的分布情况
- Orion GPU节点列表:通过点击展开可以看到一组GPU节点的状态,并且在每个节点的工作面板上看到物理GPU的划分使用情况
部署 Orion Client
环境依赖
- g++ 4.8.5 或以上版本,libcurl,openssl,libuuid, libibverbs1
软件安装
在CUDA应用环境执行如下的安装命令
cd /root/orion/client
sudo ./install-client-x.y
上述命令的x,y为根据所需 CUDA 版本选择对应的 installer,例如install-client-10.0 对应于 CUDA 10.0
上述命令把 Orion Client 环境安装至默认路径 /usr/lib/orion 中,并通过 ldconfig 机制将 /usr/lib/orion 添加到系统动态库搜索路径。
注意:如果Orion Client按照到和GPU同样的宿主机环境,由于Orion Client安装的 /usr/lib/orion 和物理GPU的 CUDA SDK可能存在版本冲突。对于同样的动态库在两个不同磁盘位置的加载顺序,应该由安装人员自己维护解决。
配置Orion Client
Orion Client可以通过三类方法配置运行参数
- 通过环境变量配置运行参数
- 通过当前用户home目录中 {$HOME}/.orion/client.conf 配置文件配置运行参数
- 通过 /etc/orion/client.conf 配置文件配置运行参数
上述方法中,通过环境变量配置的优先级最高,系统 /etc/orion 目录中配置文件的优先级最低
Orion Client的配置中分为静态配置部分和动态配置部分。
- 静态配置部分指的是在目标环境中每次运行CUDA应用程序都保持不变的部分。
- 动态配置部分指的是根据CUDA应用程序使用的Orion vGPU资源不同而不同的配置。
配置文件的格式为:
[log]
log_with_time = true ; 记录日志的时候是否添加时间戳
log_to_screen = true ; 日志是否输出到屏幕的标准输出
log_to_file = true ; 是否记录日志至磁盘文件中
log_level = INFO ; 日志级别,支持 INFO, DEBUG
file_log_level = INFO ; 日志输出到文件中的日志级别
[controller]
controller_addr = 127.0.0.1:9123 ; Orion Controller的调度器IP地址和端口
[client]
enable_net = false ; 是否使用TCP网络和Orion Server通讯
其中环境变量 ORION_CONTROLLER 设置 Orion Controller 的地址具有比配置文件更高的优先级
例如在当前SHELL通过 export ORION_CONTROLLER 环境变量可以忽略配置文件中的controller_addr配置
动态配置包括:
- 环境变量 ORION_VGPU 设置当前环境下 CUDA 应用程序申请使用多少个 Orion vGPU
- 例如通过 export ORION_VGPU=2 指定了当前 CUDA 应用程序申请使用 2 个Orion vGPU
- 该配置无默认值
- 环境变量 ORION_GMEM 设置当前环境下,CUDA 应用程序申请使用的每个 Orion vGPU 中的显存大小。以MiB为单位。
- 例如通过 export ORION_GMEM=4096 为当前 CUDA 应用程序指定了每个 Orion vGPU的显存大小为 4096 MiB。
- 该配置的默认值取决于默认一个物理GPU被切分为几个vGPU
- 环境变量 ORION_RATIO 设置当前环境下,CUDA 应用程序申请使用的每个 Orion vGPU 占用一个物理GPU算力的百分比。以%为单位
- 例如通过 export ORION_RATIO=50 为当前 CUDA 应用程序指定了每个 Orion vGPU的50%的算力。
- 该配置的默认值取决于默认一个物理GPU被切分为几个vGPU
- 环境变量 ORION_CROSS_NODE 为可选参数,参数为1且申请多个vGPU时,允许Orion Controller跨越多个物理GPU节点调度资源,使得分配的多个vGPU可能来自于不同的物理GPU节点。
- 该参数为1时,ORION_RATIO必须为100
- 该配置默认为0
Orion Client日志
Orion Client日志位于执行应用程序的用户home目录中的 ${HOME}/.orion/log 目录中。每次CUDA应用运行均会在该目录产生一个对应于该次任务的日志文件。
使用Orion vGPU
本章节介绍在Orion Client环境中,如何为CUDA应用程序配置使用Orion vGPU
Orion vGPU资源
通过安装部署Orion vGPU软件,所有Orion Server所在的GPU服务器内的GPU均加入了一个全局共享的资源池。每个物理GPU均被划分为多个逻辑vGPU。划分vGPU的默认粒度为启动 Orion Server 时,配置文件 /etc/orion/server.conf 中的 vgpu_count 参数指定。若设置 vgpu_count=n,则每个vGPU默认的显存大小为物理GPU显存的 n 分之一。
Orion vGPU的使用
由于Orion vGPU的调用接口兼容物理GPU的调用接口,因此CUDA应用程序可以无感知无修改地像使用物理GPU那样使用Orion vGPU。仅需要在运行CUDA应用程序时,通过配置文件、环境变量为本CUDA应用程序配置运行环境即可。
经过Orion GPU资源池化之后,资源池中的vGPU使用模式为CUDA应用程序即时申请即时使用的模式。也即是当CUDA应用程序调用CUDA接口初始化时才向Orion GPU资源池申请一定数量的vGPU,当CUDA应用程序退出时其申请到的vGPU自动释放至资源池中。多次调用CUDA应用程序分配到的vGPU不一定对应于同样的物理GPU资源。
当Orion Client的静态环境配置完毕后,在运行一个CUDA应用之前,至少需要用 ORION_VGPU 环境变量指明该CUDA应用程序希望获得的vGPU数目。例如一个deviceQuery CUDA程序,如下的命令使得当该CUDA程序做设备发现时,通过CUDA的接口查询到2个GPU,每个GPU的显存是4096MiB。
export ORION_VGPU=2
export ORION_GMEM=4096
./deviceQuery
当上述deviceQuery CUDA程序启动时,会从Orion GPU资源池中独占两个vGPU。该程序结束时,会自动释放两个vGPU。可以通过重新设定环境变量,在运行CUDA应用程序之前改变对vGPU资源的使用。一次CUDA应用程序所申请的多个vGPU可能存在于多个物理GPU上。
vGPU的使用对象为CUDA应用程序,而非物理机、Container或者VM虚拟机。即使在同一个环境下运行的多个CUDA应用程序,每一个应用程序都按照当前的运行环境向Orion GPU资源池申请独立的vGPU资源。如果并行运行多个CUDA应用程序,则消耗的vGPU数量为应用程序数目乘以 ORION_VGPU 所指定的vGPU数目。
常见问题
用户首先需要确认Orion Server和Orion Client版本的匹配。不同版本之间的Orion Server和Orion Client无法共同使用。
Orion Client端应用程序启动报告无法找到NVidia GPU
- 此故障为应用程序没有使用Orion Client运行库导致,可能的原因有几种:
- 该应用程序在编译期间静态链接了NVidia的库,导致其运行时并不调用Orion Client的运行库。该问题应该通过设置动态链接并重新编译解决。
- 该应用程序虽然使用CUDA相关的动态链接库,但是编译器使用rpath选项指明了CUDA库加载的绝对路径,而该路径并非是Orion Client的安装路径。rpath优先级高导致库加载的路径非期望的Orion Client安装路径。该问题或者通过去掉rpath设置后重新编译解决,或者用Orion Client运行库覆盖rpath指明的路径内的库解决。
- Orion Client库的安装路径没有使用ldconfig或者环境变量LD_LIBRARY_PATH放到动态库加载路径。该问题通过使用ldconfig永久把Orion Client的安装路径加入到系统搜索路径,或者正确使用环境变量LD_LIBRARY_PATH来设置。
- 此故障为应用程序没有使用Orion Client运行库导致,可能的原因有几种:
Orion Server服务无法启动,oriond进程启动失败
- 通过运行 orion-check runtime server 来检查环境。可能的原因有
- oriond进程依赖CUDA,CUDNN库无法搜索到导致可执行文件无法被操作系统启动。
- 修改上述Orion Server服务配置文件
- oriond进程依赖的其他库没有安装,例如libcurl,libopenssl等
OrionX 部署指南(适用于 Red Hat)
环境要求
操作系统
- RHEL 7 / 8 / 9(建议使用 SELinux 关闭或 permissive 模式)
软件要求
- Docker ≥ 1.13(已安装并运行)
- NVIDIA GPU 驱动(与所用 CUDA 版本匹配)
- NVIDIA Docker Runtime
- CUDA Toolkit(支持版本:9.0–10.1)
- CUDNN ≥ 7.4.2(建议 7.6+)
- NCCL(与 CUDA 匹配)
- containerd ≥ 1.3.2
硬件要求
- 安装有 NVIDIA GPU 的服务器
- 支持 RDMA 的 Mellanox 网卡(可选)
文件结构约定
以下操作假定 OrionX软件包位于 /root/orion/ 目录下:
/root/orion/
├── gpu-monitor/
├── controller/
├── server/
└── client/
安装步骤
- GPU Monitor(可选)
cd /root/orion/gpu-monitor
gunzip dcgm-exporter.tar.gz | docker load
gunzip node-exporter.tar.gz | docker load
./run-nvidia-exportor.sh
- OrionX Controller
cd /root/orion/controller
gunzip orion-controller-ent-2.2.tar.gz | docker load
gunzip prometheus.tar.gz | docker load
./run-controller.sh
# 修改 prometheus.yml 中的 targets 字段以匹配 GPU Monitor 地址
# 日志文件:/root/controller.log
- OrionX Server
cd /root/orion/server
sudo ./install-server.sh
# 编辑配置文件 /etc/orion/server.conf 示例:
[server]
vgpu_count = 4
bind_addr = 192.168.1.100
listen_port = 9960
enable_kvm = true
enable_shm = true
enable_rdma = true
[controller]
controller_addr = 192.168.1.1:9123
# 启动服务
sudo systemctl start oriond
- OrionX Client
cd /root/orion/client
sudo ./install-client-10.1
# 设置环境变量
export ORION_VGPU=2
export ORION_GMEM=4096
export ORION_RATIO=100
export ORION_CONTROLLER=192.168.1.1:9123
# 日志位置:${HOME}/.orion/log/
OrionX vGPU 使用方式
export ORION_VGPU=2
export ORION_GMEM=4096
./deviceQuery
# 每次运行自动申请和释放 vGPU 资源,应用程序无需修改。
常见问题
- License 无效导致服务无法启动:检查 license.txt
- 绑定网卡失败:确认所有节点使用相同网卡名称(如 eth0)
- GPU 利用率无法显示:检查 Prometheus 与 RDMA 配置
- 日志未记录:确认日志路径权限和配置项
示例:Jupyter Notebook 使用 OrionX vGPU
pip3 install notebook
jupyter notebook --ip=0.0.0.0 --no-browser --allow-root
# 本地 SSH 转发方式访问
ssh -Nf -L 8888:localhost:8888 user@client-machine
OrionX 在 OpenShift 上的集成指南
简介
OrionX 是一套 GPU 资源池化与虚拟化解决方案,支持多种调度方式与硬件资源配置方式。本文档旨在指导用户如何在 Red Hat OpenShift 平台上集成部署 OrionX,实现 GPU 的精细化分配与跨节点调度。
系统环境要求
依赖组件
- OpenShift 版本 >= 4.x
- NVIDIA GPU 驱动已安装并正确加载
- NVIDIA Container Toolkit 安装完毕
- containerd 或 CRI-O 作为容器运行时,支持 NVIDIA runtime
- 所有 GPU 节点需具备统一的网络接口名(如 eth0)
- Red Hat 系统需启用以下软件包:kernel-devel、gcc、make、libibverbs、numactl
集成步骤
第一步:准备镜像与资源目录
在所有准备集成的 OpenShift 节点中,创建资源存放目录:
mkdir -p /root/orion/{controller,server,client,gpu-monitor}
上传并解压 OrionX 提供的安装包,并将对应的 tar 镜像包、脚本文件解压至对应目录中。
第二步:部署 GPU Monitor(可选)
cd /root/orion/gpu-monitor
gunzip dcgm-exporter.tar.gz | podman load
./run-nvidia-exportor.sh
此服务用于采集 GPU 物理利用率,如已有 Prometheus/Grafana,可忽略部署。
第三步:部署 OrionX Controller
- 获取激活文件 license.txt,放入 /root/orion/controller/
- 加载镜像并运行服务:
cd /root/orion/controller
gunzip orion-controller-ent-2.2.tar.gz | podman load
gunzip prometheus.tar.gz | podman load
./run-controller.sh
- 修改配置文件 prometheus.yml,确保 static_configs 的 targets 与 GPU 节点的 bind_addr 匹配。
第四步:在 GPU/CPU 节点部署 OrionX Server
cd /root/orion/server
sudo ./install-server.sh
#编辑配置文件 /etc/orion/server.conf,重点参数如下:
[controller]
controller_addr = <Controller_IP>:9123
[server]
bind_addr = <本机内网IP>
vgpu_count = 4
enable_rdma = true
enable_shm = true
enable_kvm = true
#启动服务:
sudo systemctl enable --now oriond
第五步:部署 OrionX Client 到用户容器
OpenShift 使用 CRI-O 容器运行时,确保 NVIDIA runtime 已启用。
#安装 Client
cd /root/orion/client
sudo ./install-client-10.1 # CUDA 版本按需选择
#设置环境变量
export ORION_VGPU=2
export ORION_GMEM=4096
export ORION_RATIO=100
export ORION_CONTROLLER=<Controller_IP>:9123
#启动测试 CUDA 程序
/root/cuda_samples/deviceQuery/deviceQuery
第六步:在 OpenShift 中定义 Deployment(示例)
apiVersion: apps/v1
kind: Deployment
metadata:
name: orion-client-test
spec:
replicas: 1
selector:
matchLabels:
app: orion-client
template:
metadata:
labels:
app: orion-client
spec:
containers:
- name: test
image: virtaitech/orion-client-2.2:cuda10.1-tf1.14-py3.6-hvd
env:
- name: ORION_VGPU
value: "2"
- name: ORION_GMEM
value: "4096"
- name: ORION_RATIO
value: "100"
- name: ORION_RESERVED
value: "0"
- name: ORION_CROSS_NODE
value: "0"
resources:
limits:
virtaitech.com/gpu: 2
nodeSelector:
kubernetes.io/hostname: <gpu-node-name>
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
注意事项
- 必须统一 GPU 节点上的网络接口名,如 eth0。
- license.txt 文件必须与版本匹配,否则组件无法正常启动。
- OpenShift 上部署需确保 SCC 策略允许容器使用 hostIPC 与挂载必要路径。
常见问题
- 日志查看路径
- Controller 日志:容器内 /root/controller.log
- Client 日志:$/.orion/log/
- Server 配置:/etc/orion/server.conf
- 网络不可达问题
- 检查 bind_addr 对应的网卡是否在 node 中存在并配置了 IP。
- License 无效问题
- 确认激活文件是否为最新版本,使用文本工具检查是否出现乱码或拷贝错误。
OrionX-Rancher集成指南
Rancher同趋动科技达成战略合作,加速GPU资源池化在Kubernetes中落地
面对Kubernetes使用GPU资源的众多难题,Rancher与趋动科技共同推出了面向Kubernetes的GPU资源池化联合解决方案。Rancher可以同时管理多个Kubernetes集群,用户可以通过其内置的应用市场Catalog开箱即用地将OrionX部署至各个业务集群,OrionX具备专业的GPU池化和虚拟化功能,可以无侵入地整合至Rancher托管的Kubernetes集群当中。最终,用户可以极为方便地在Rancher平台上进行GPU资源调度,从而让工作负载使用OrionX提供的vGPU资源。
1. 使用Rancher中国提供的pandaria-catalog应用商店
OrionX现已集成至Rancher中国的应用市场当中,开源用户可以通过导入pandaria-catalog(https://github.com/cnrancher/pandaria-catalog)获取这一应用,企业用户无需导入即可轻松使用。
Rancher中国企业版使用pandaria-catalog应用商店
Rancher中国企业版已默认集成pandaria-catalog应用商店。请使用v2.3.8-ent以上版本,该版本已经实现了工作负载对OrionX vGPU的支持,运行方式:
sudo docker run -d --restart=unless-stopped -p 80:80 -p 443:443
cnrancher/rancher:v2.3.8-ent
在全局— 工具— 商店设置中,查看应用商店,企业版已经内置了pandaria-catalog,并在其中
内置了OrionX Chart 。如图所示:
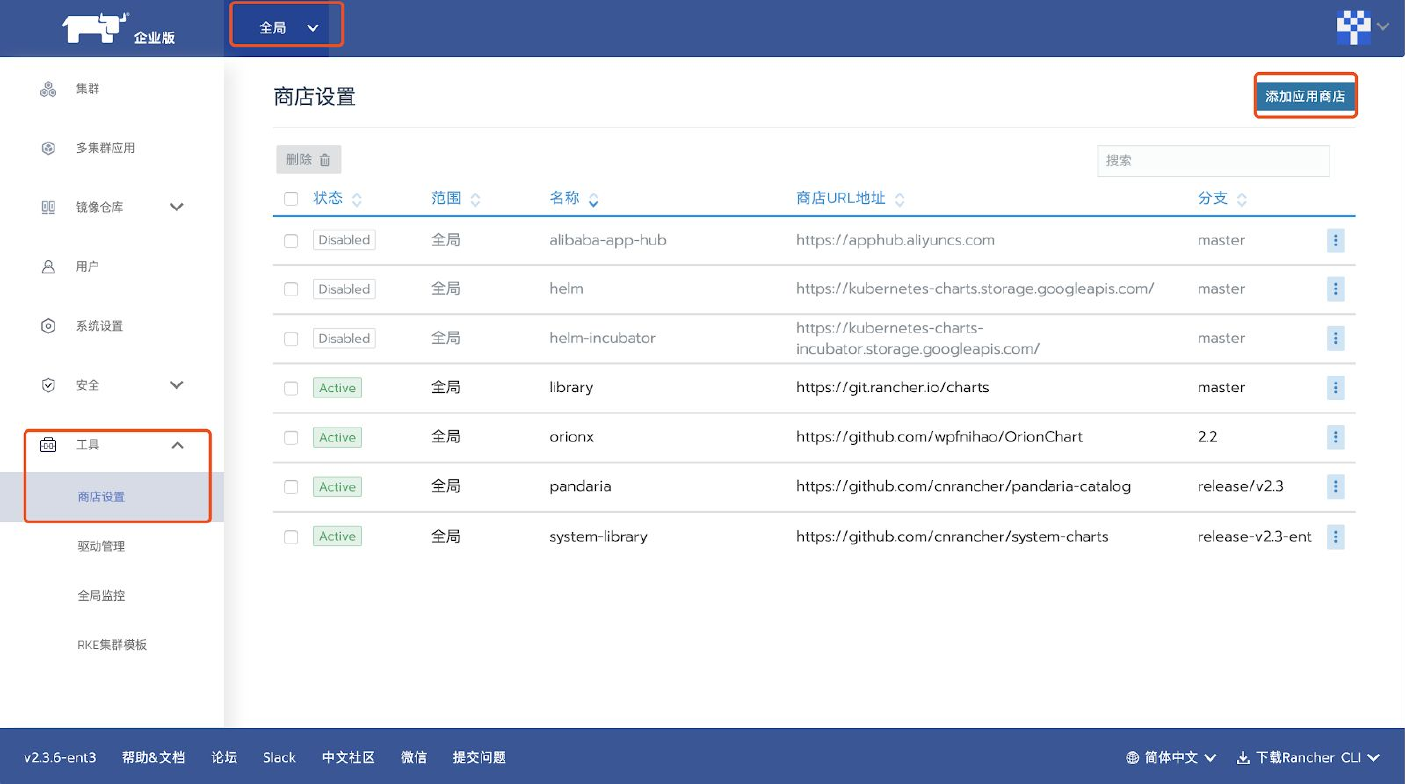
可以看到pandaria-catalog已经处于Active激活状态。
进入应用商店,可以看到virtaitech-orion-vgpu应用。如图所示:
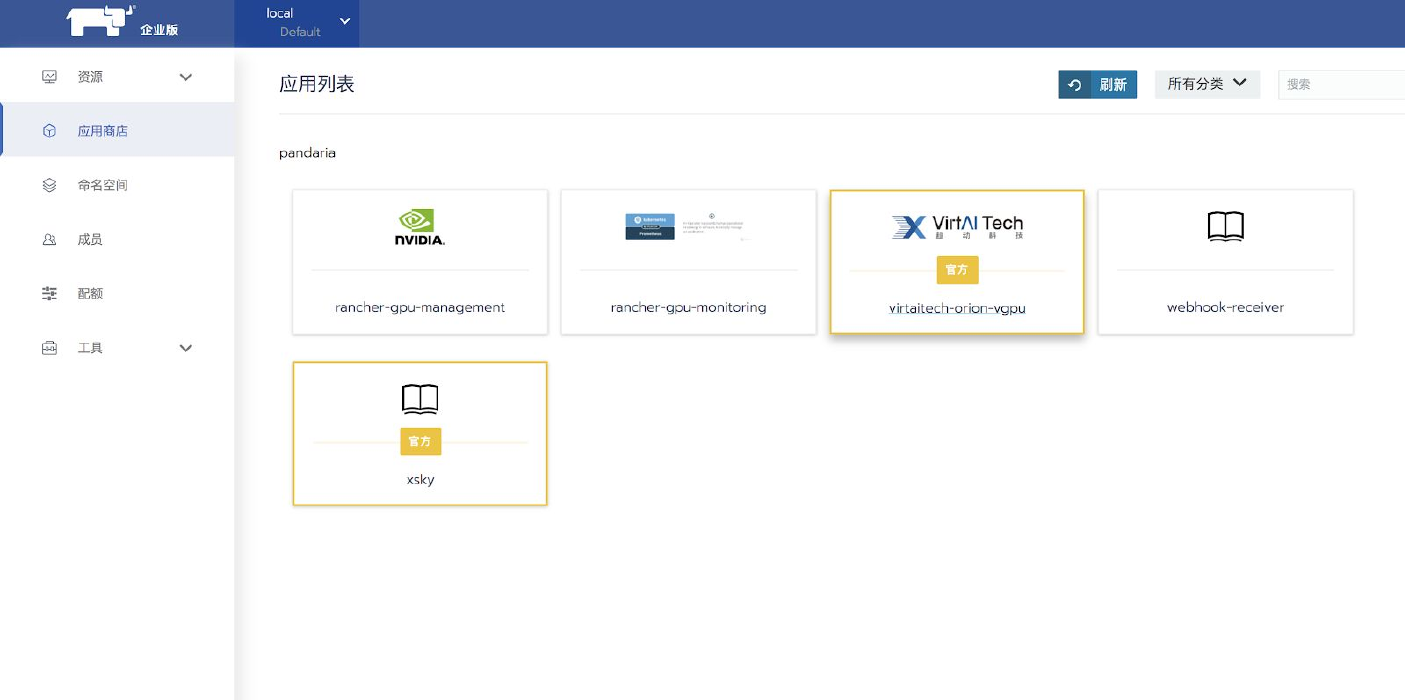
Rancher社区版使用pandaria-catalog应用商店
Rancher社区版(https://rancher.com/quick-start/)也可以方便的一键部署:
sudo docker run -d --restart=unless-stopped -p 80:80 -p 443:443 rancher/rancher
但是Rancher社区版并没有默认配置pandaria-catalog应用商店,需要用户手动配置。
进入
Global-Apps-Manage Catalogs页面: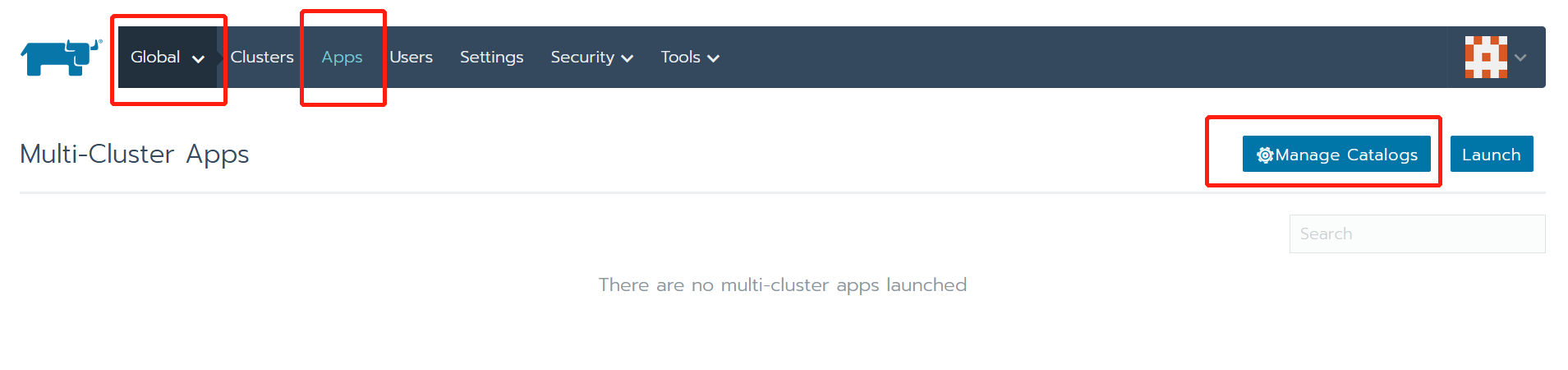
添加catalog。如图所示,首先点击
Add Catalog按钮。填入Catalog URL=https://github.com/cnrancher/pandaria-catalog和Branch=dev/v2.3。名称可以随意设置,范围Scope则最好设置为全局global。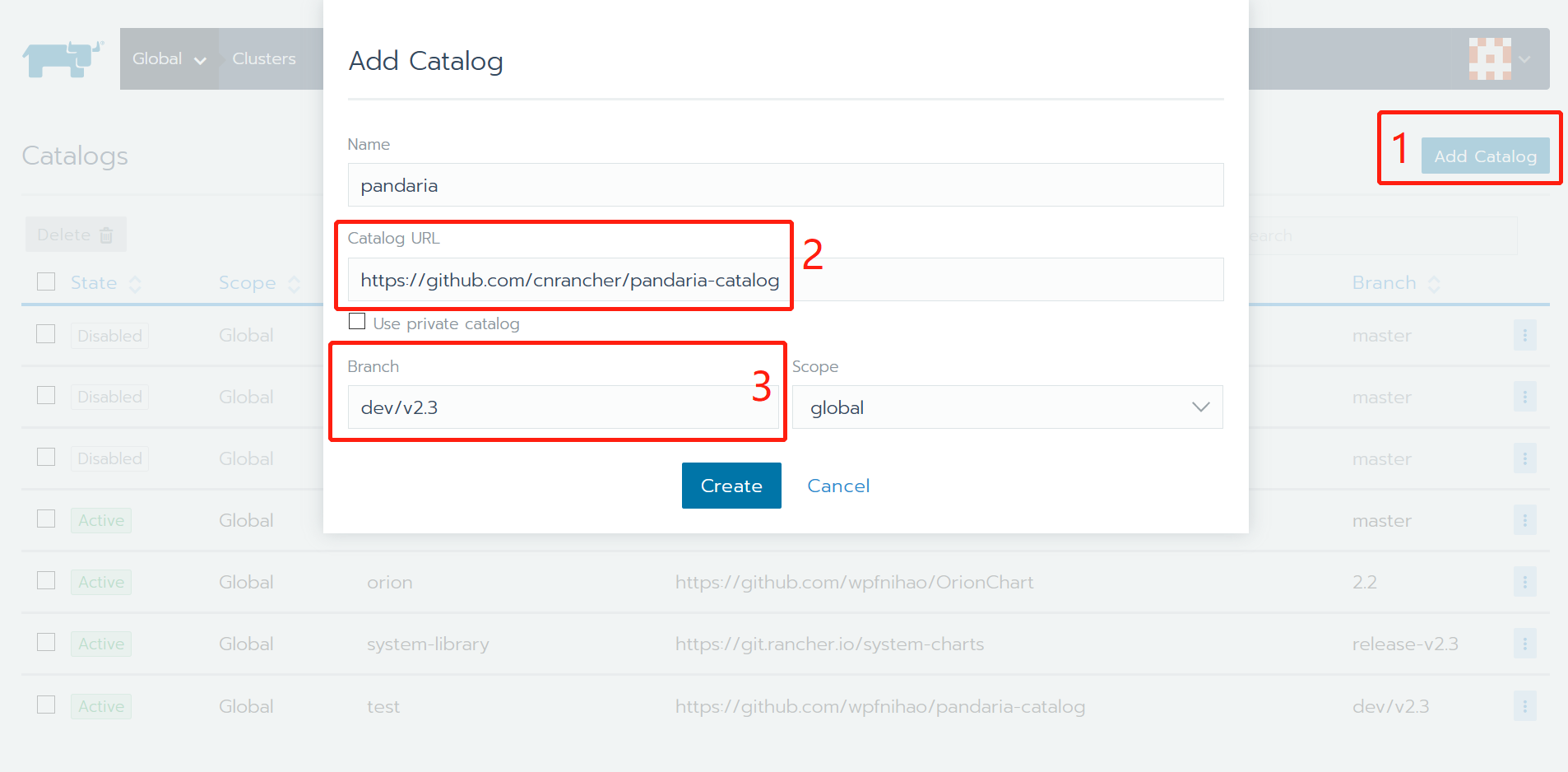
此时catalog配置完成,可以去应用商店进行确认。
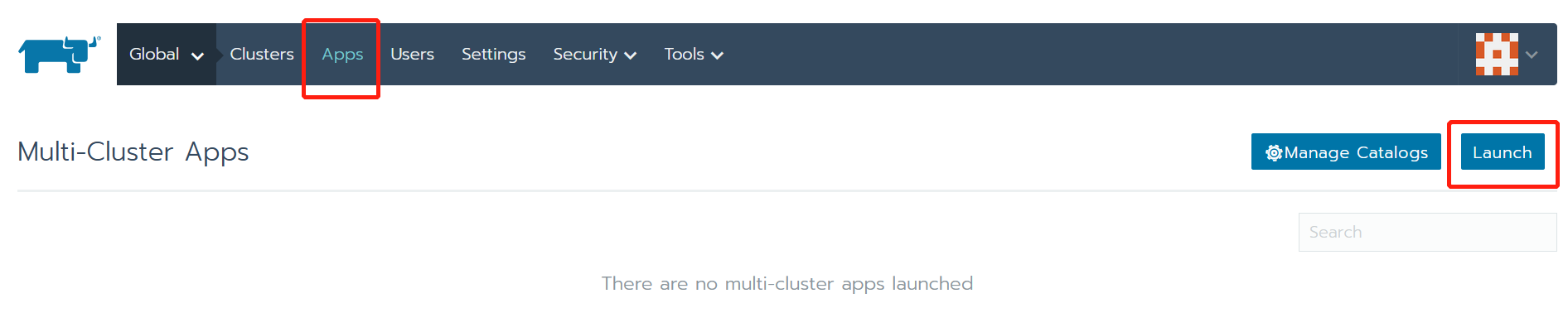
可以看到
virtaitech-orion-vgpu已经出现在应用商店内。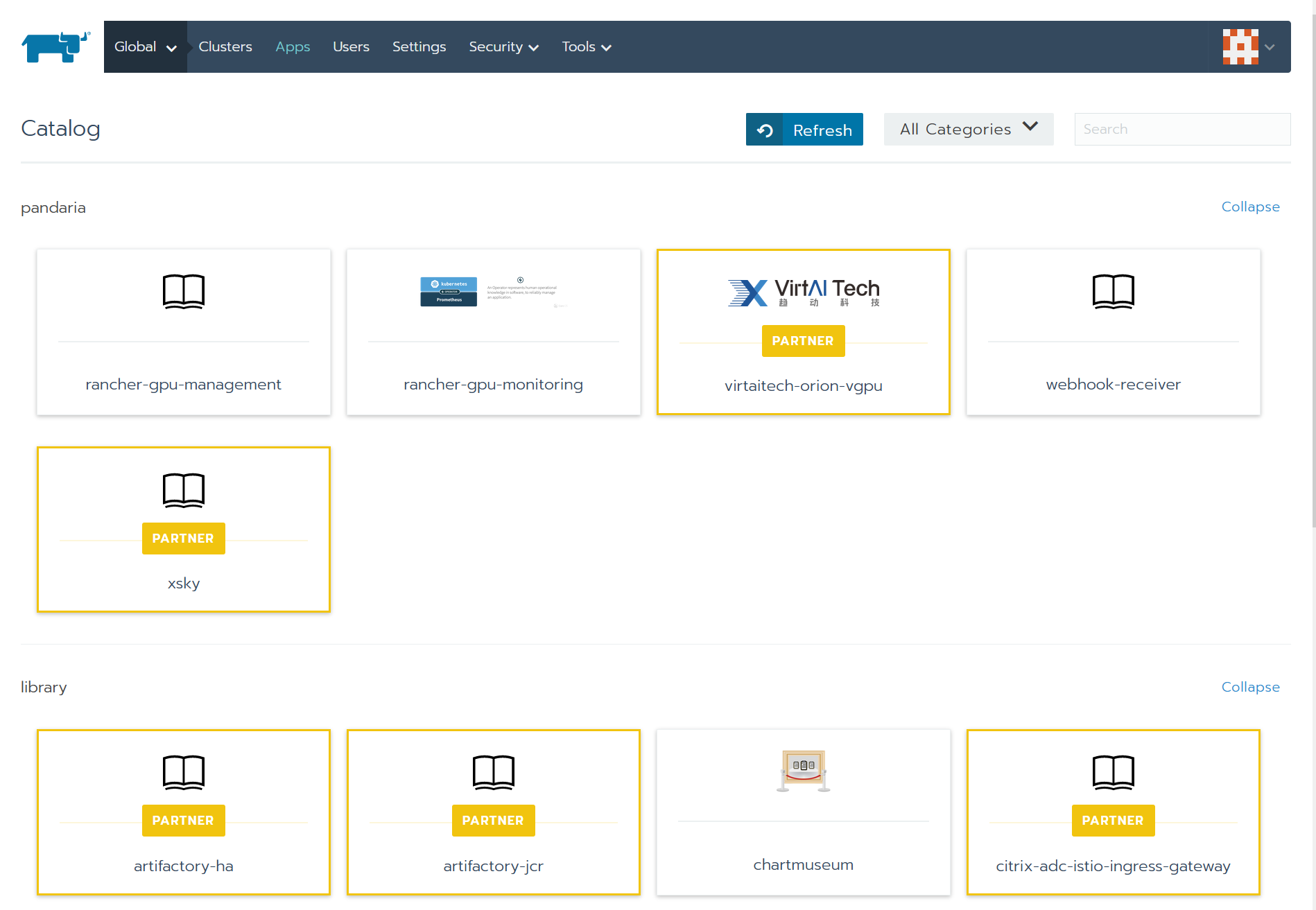
2. 环境要求
在部署OrionX之前,客户环境需要满足一定条件:
- 部署OrionX的Kubernetes版本需要>=1.6。OrionX会部署一个专用调度器
orion-scheduler,需要Kubernetes v1.6及以上版本支持。具体请参考这里和这里。 - 客户环境需要确保相应硬件的驱动已正确安装,特别是NVidia GPU驱动。如果使用RDMA网卡,还需要确保RDMA驱动已正确安装。
- 容器运行时
containerd版本号>= 1.3.2。- 在GPU节点上安装好了
NVidia docker runtime,并且已经设置为默认容器运行时。可以通过kubectl describe node [nodename]来检测节点的容器运行时。
- 在GPU节点上安装好了
- (关键)OrionX要求所有节点上用于OrionX通信的网卡使用相同名称(例如
eth0)。用户务必确保这一前置条件满足,否则Orion Server在没有正确配置网卡名称的节点上无法正确启动。请参考下文常见问题一节。 - (推荐)如果使用Mellanox RDMA网络,需要安装RDMA驱动,以及Mellanox的OFED。
3. 部署OrionX
Rancher中国企业版部署OrionX
选择需要部署的Kubernetes集群和对应Project,点击启动:
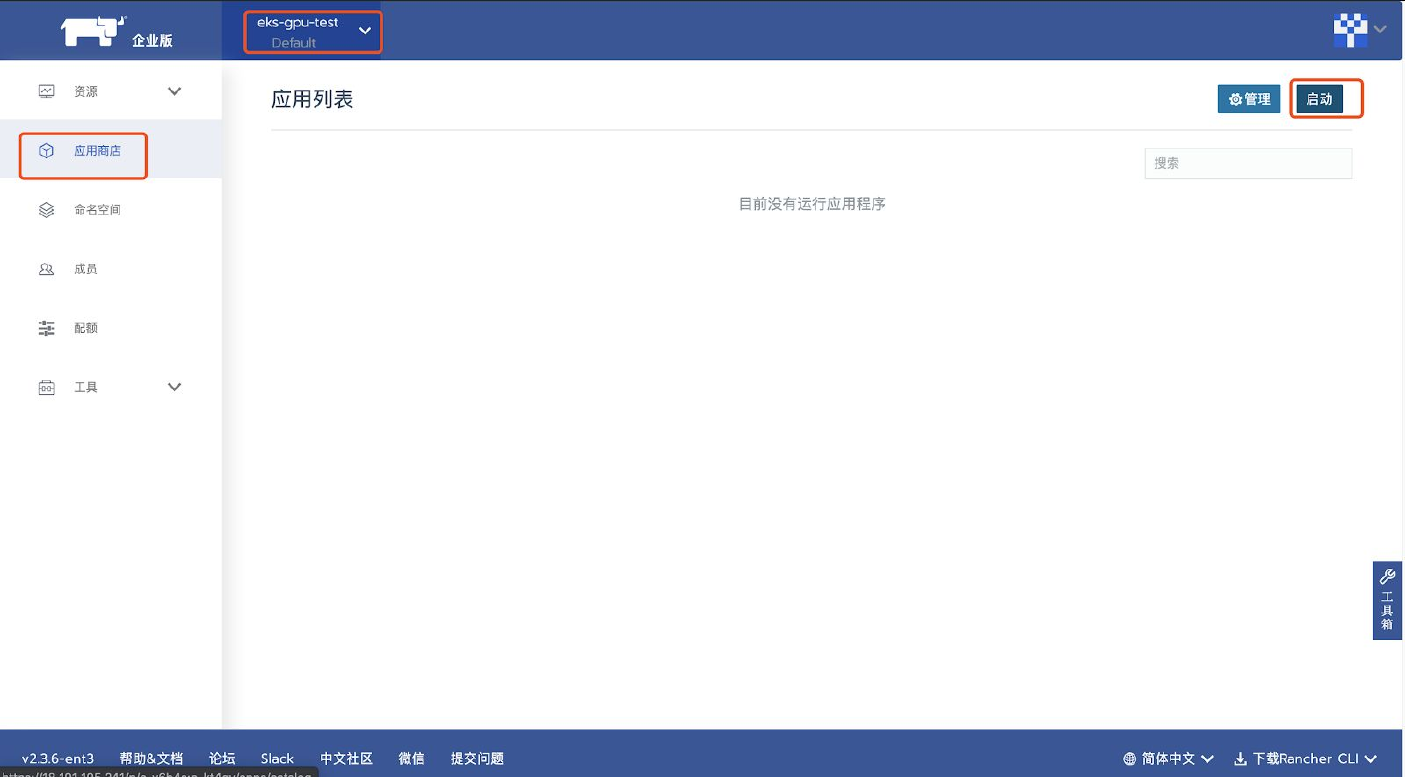
选择
virtaitech-orion-vgpu:
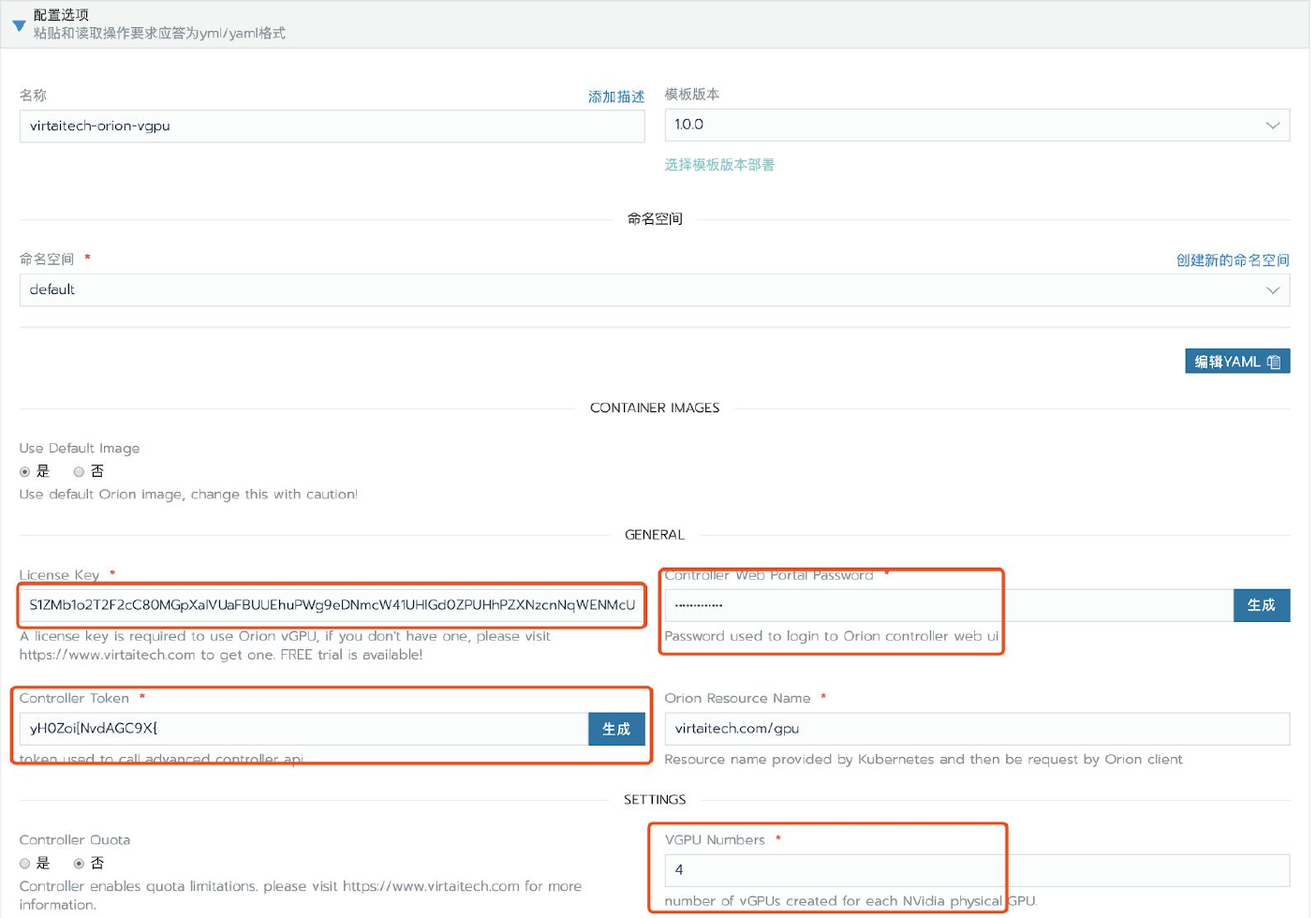
在部署表单内对OrionX进行配置。具体配置内容请参考下文配置详情一节。
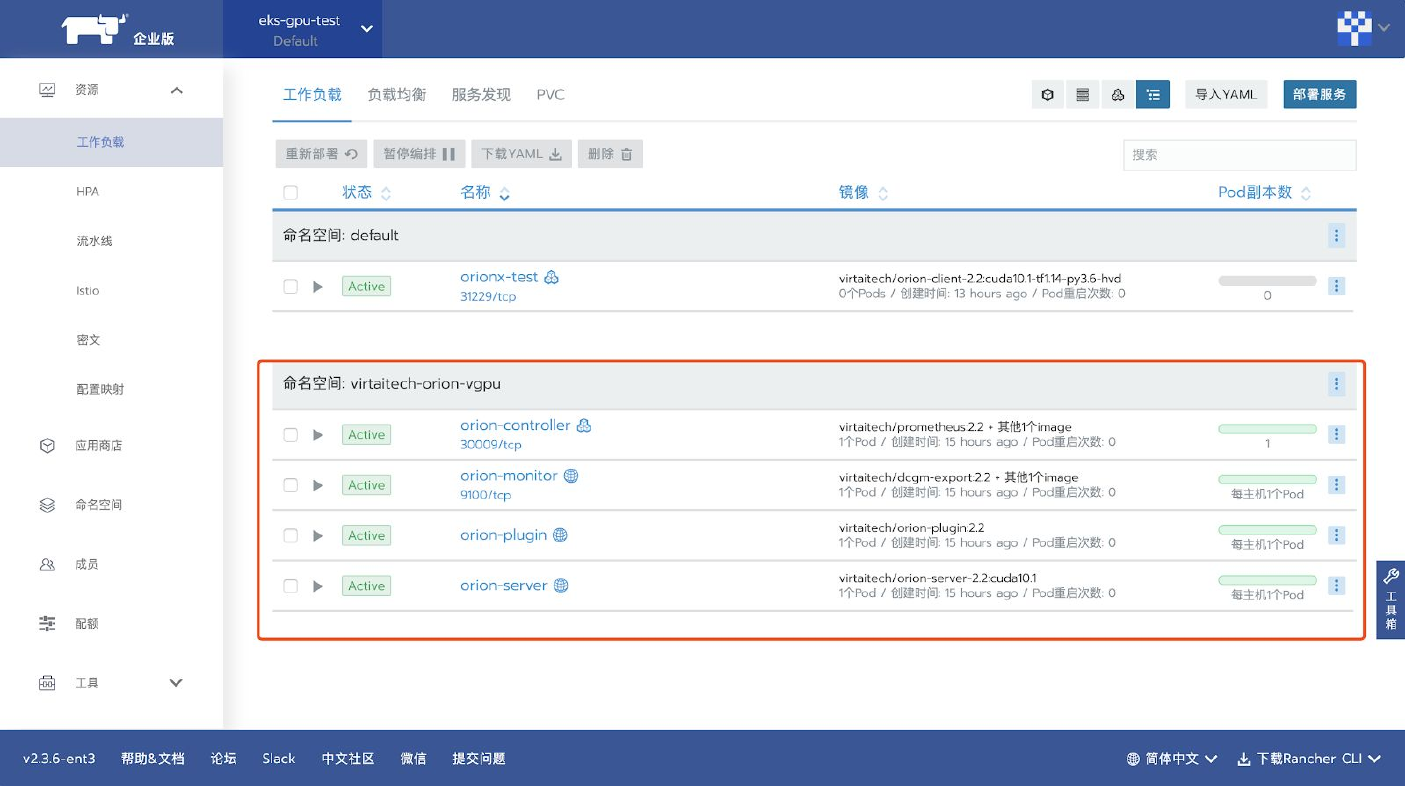
Rancher会自动拉取OrionX的所有组件镜像,用户可以在Rancher内查看所有组件的运行状态。
- 注:新版OrionX只会部署在一个命名空间(namespace)内。
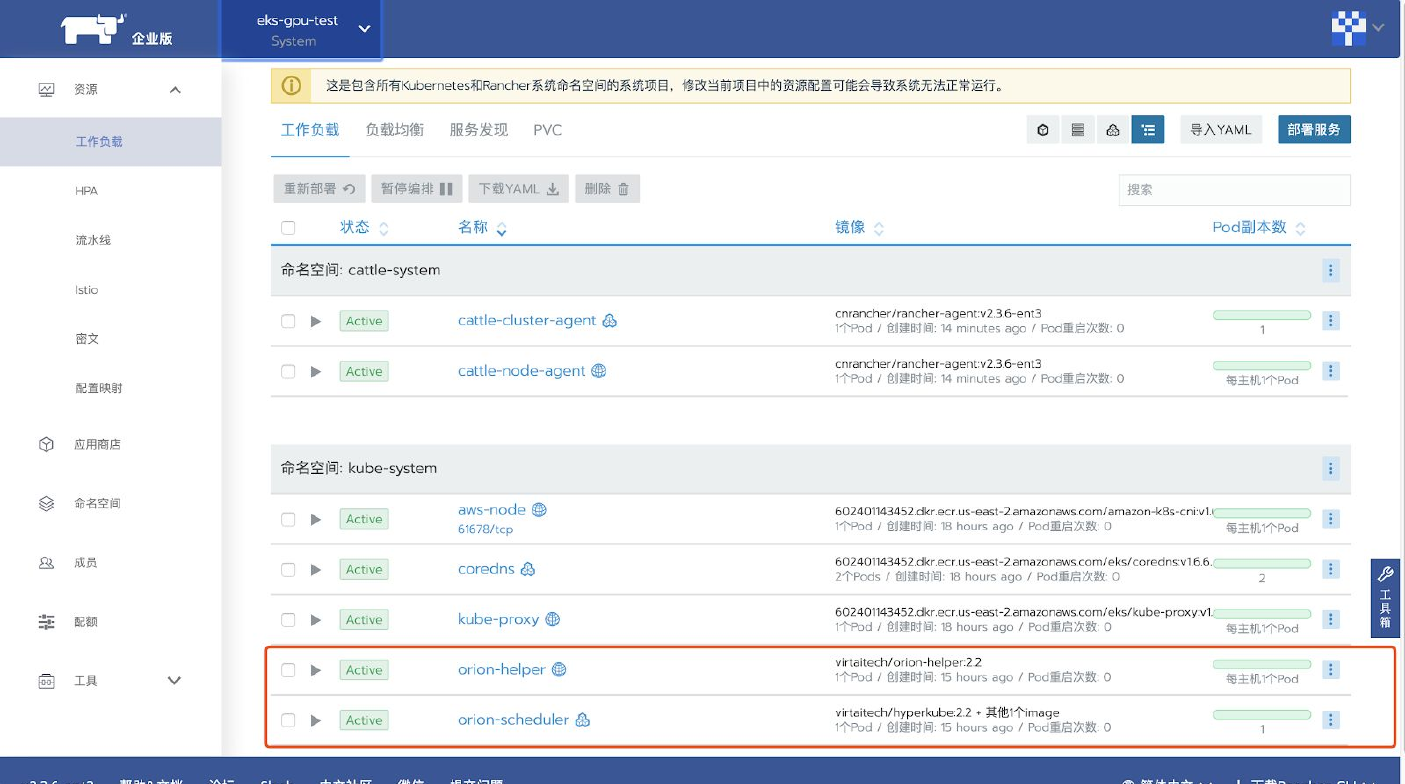
Rancher社区版部署OrionX
在执行下述步骤之前,请务必参照Rancher社区版使用pandaria-catalog应用商店一节正确配置应用商店。
选择要部署Orion的集群,以及对应的project。选择Apps,点击Launch。

选择
virtaitech-orion-vgpu。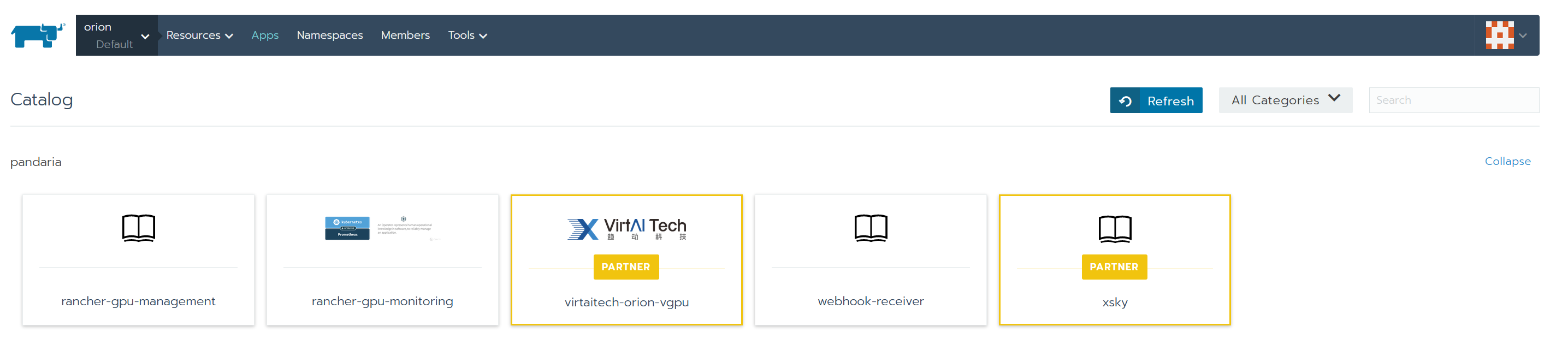
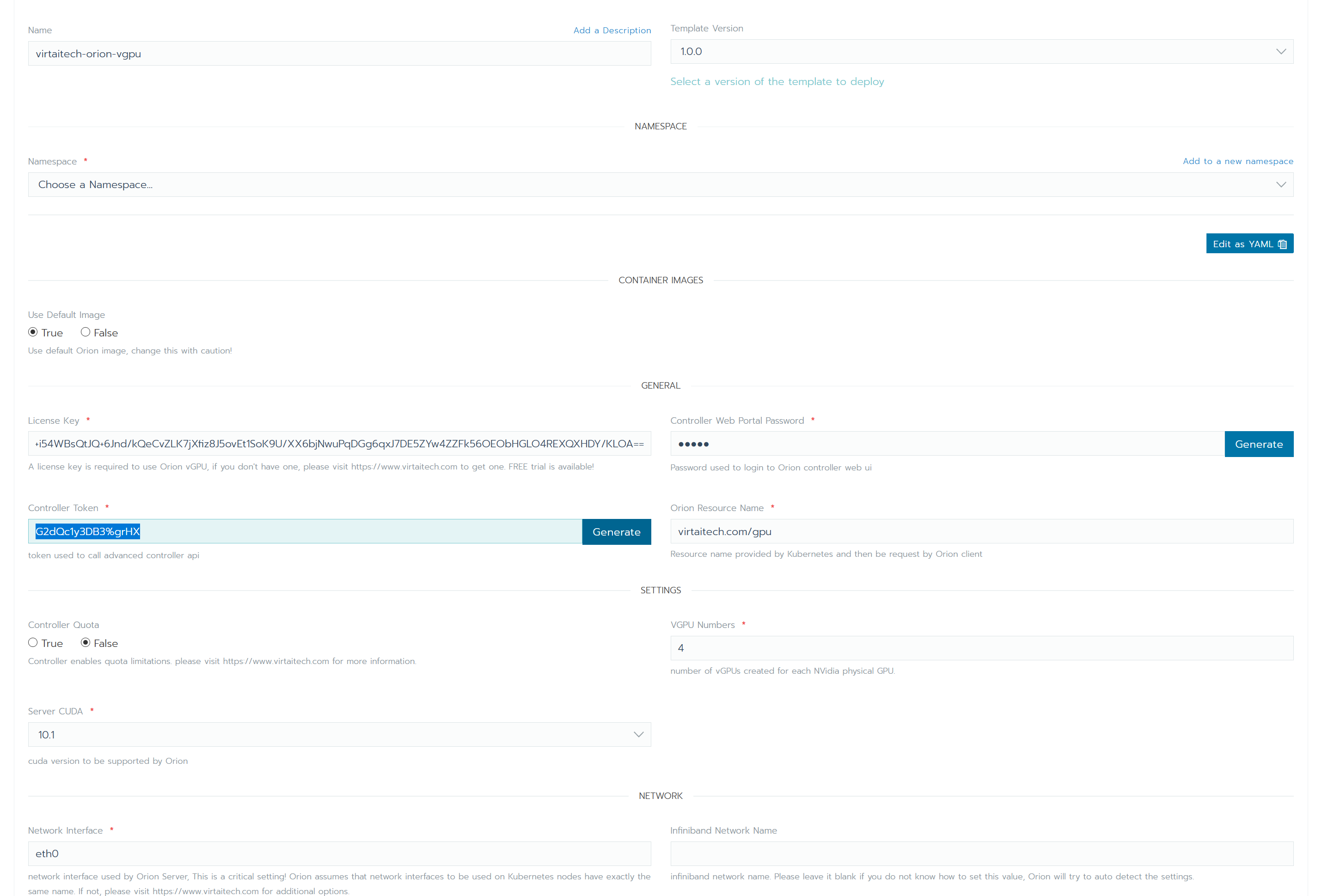
在部署表单内对OrionX进行配置。具体配置内容请参考下文配置详情一节。
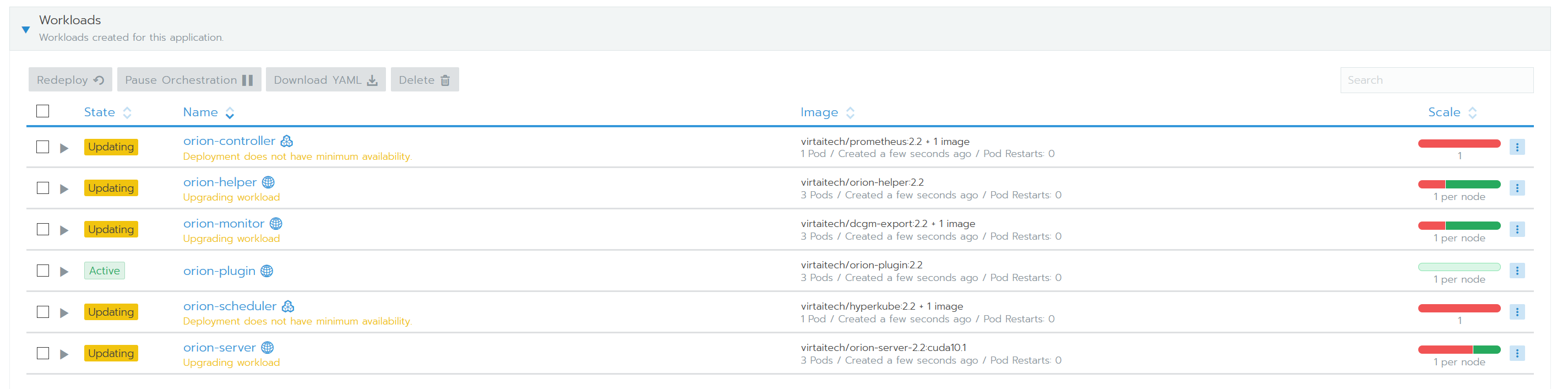
查看所有OrionX组件的状态。
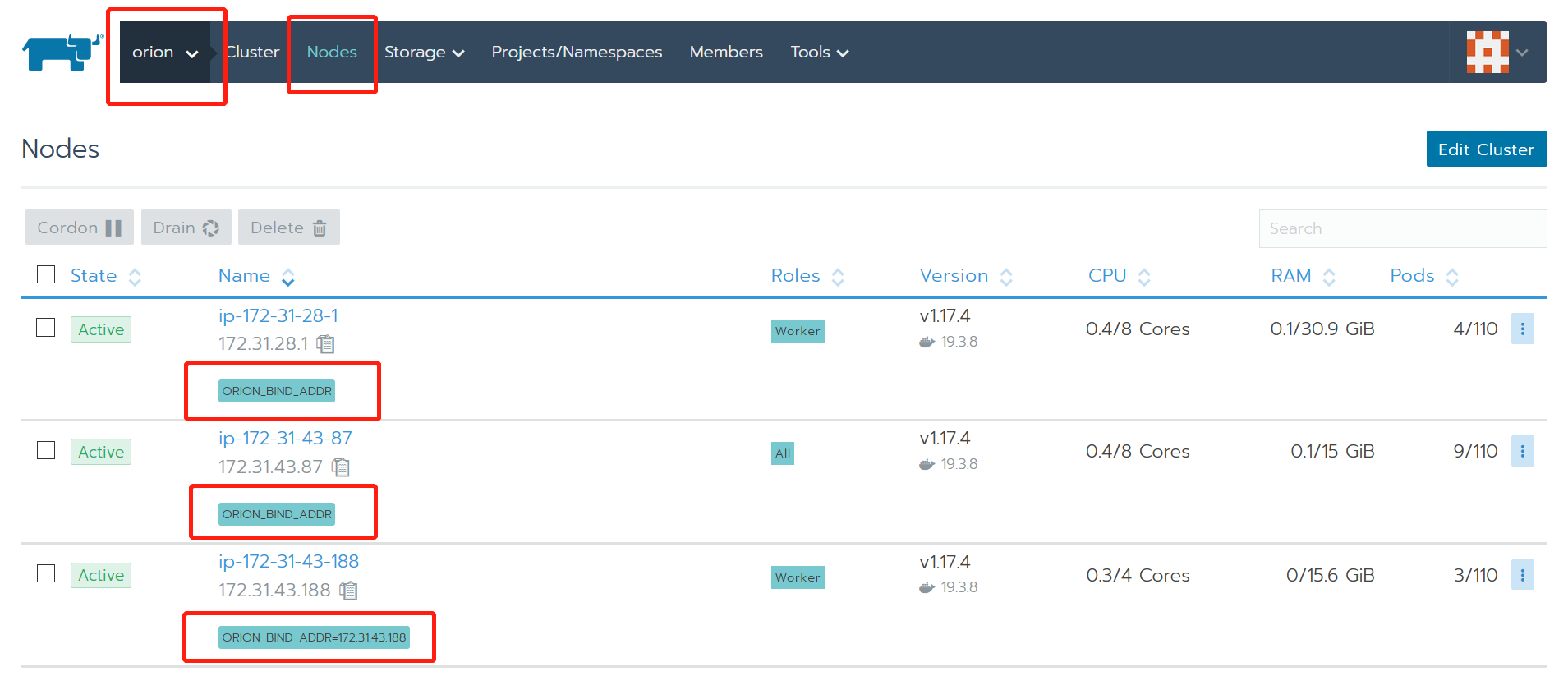
检查节点标签
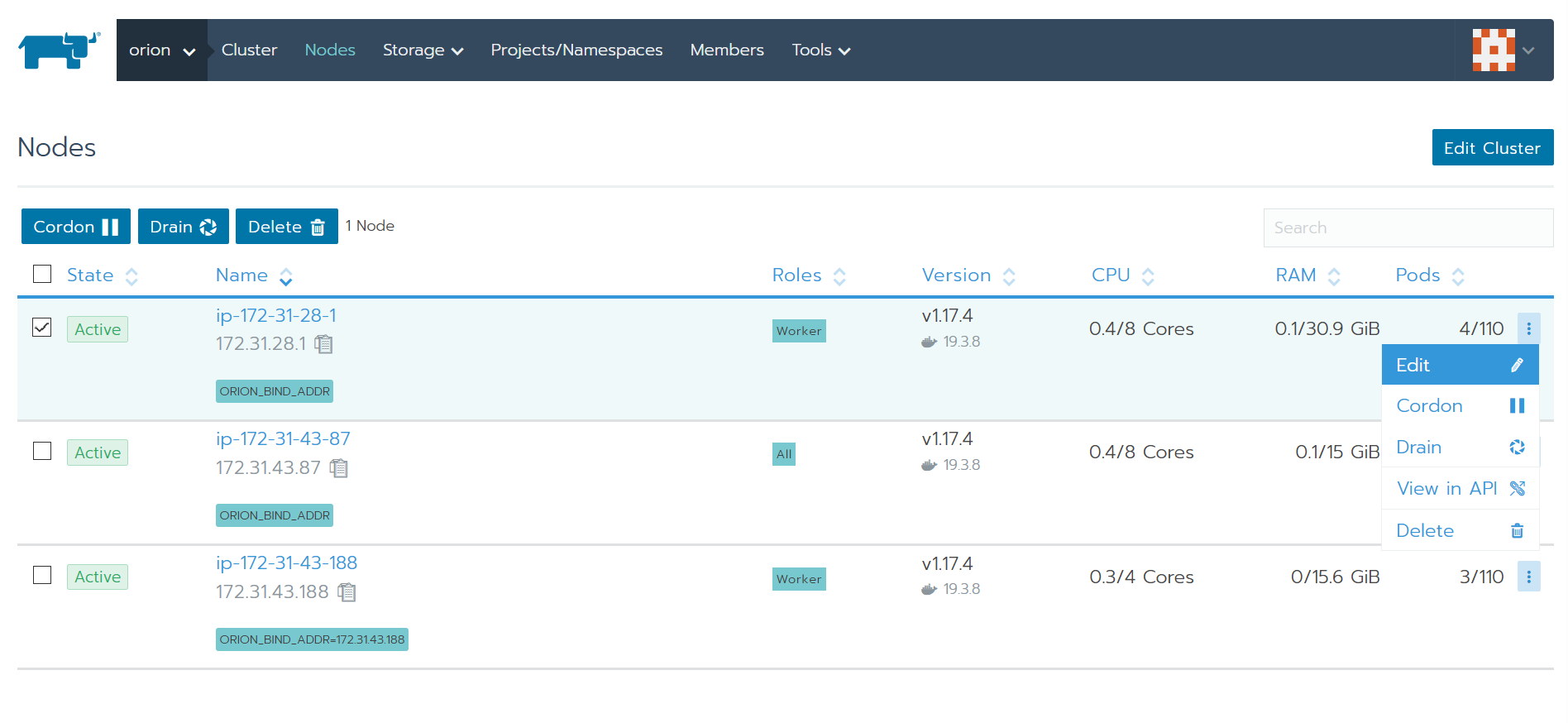
orion-helper会依据用户配置的Network Interface(例如eth0)自动获取ip地址,并给Kubernetes节点打上标签。可以在集群-Nodes页面查看到节点的标签。所有需要运行orion-server的节点都需要有正确的ORION_BIND_ADDR标签。如下图所示,只有一个节点ip-172-31-43-188正确标识了ORION_BIND_ADDR的值。ORION_BIND_ADDR没有获取到正确的值通常是因为Network Interface(例如eth0)与该节点的网卡名称不匹配导致的。ORION_BIND_ADDR的值未正确设置会在某些情况下影响OrionX的性能。
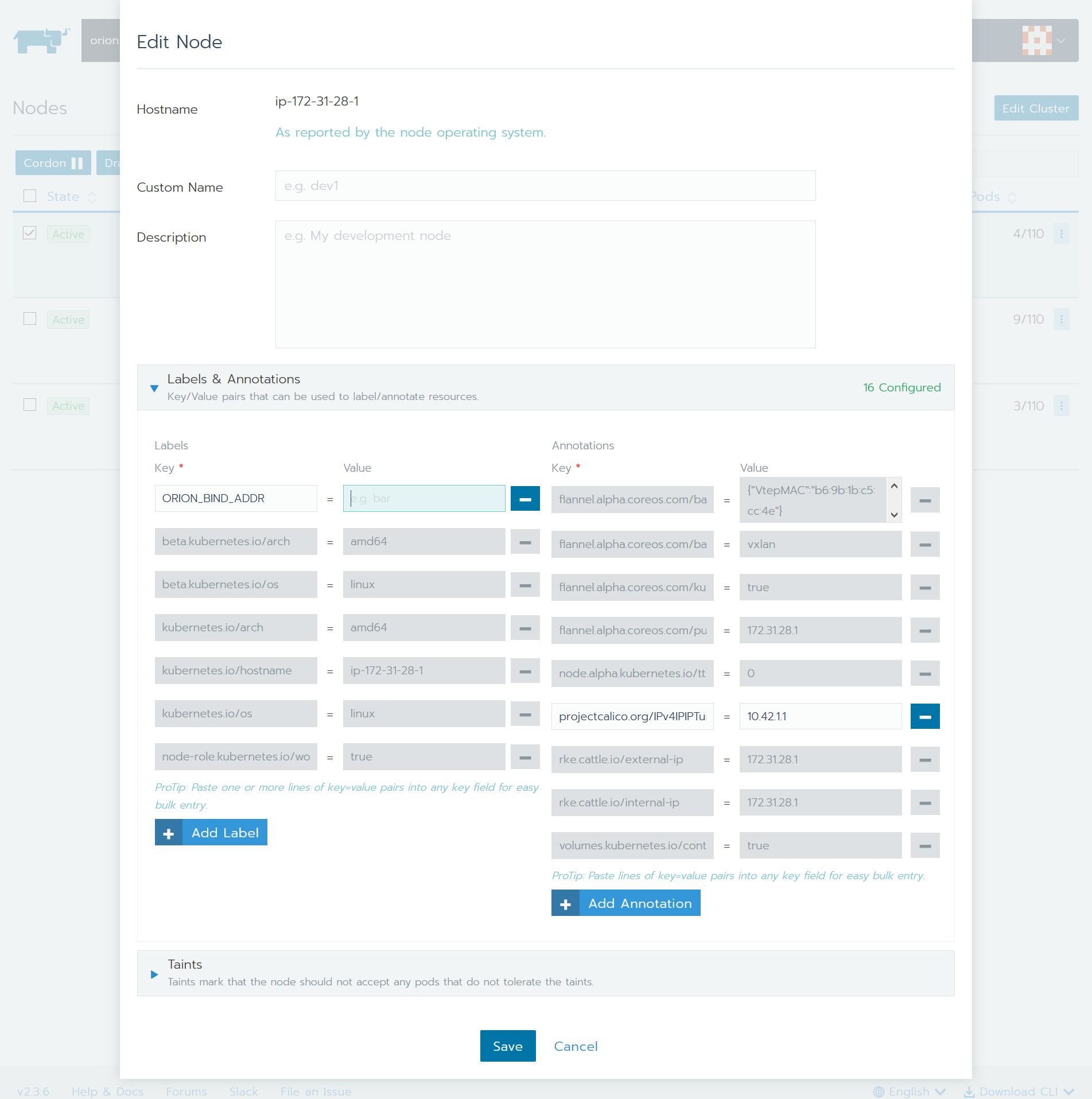
用户可以通过Rancher上手动修改节点标签,如下图所示:
查看部署相关信息
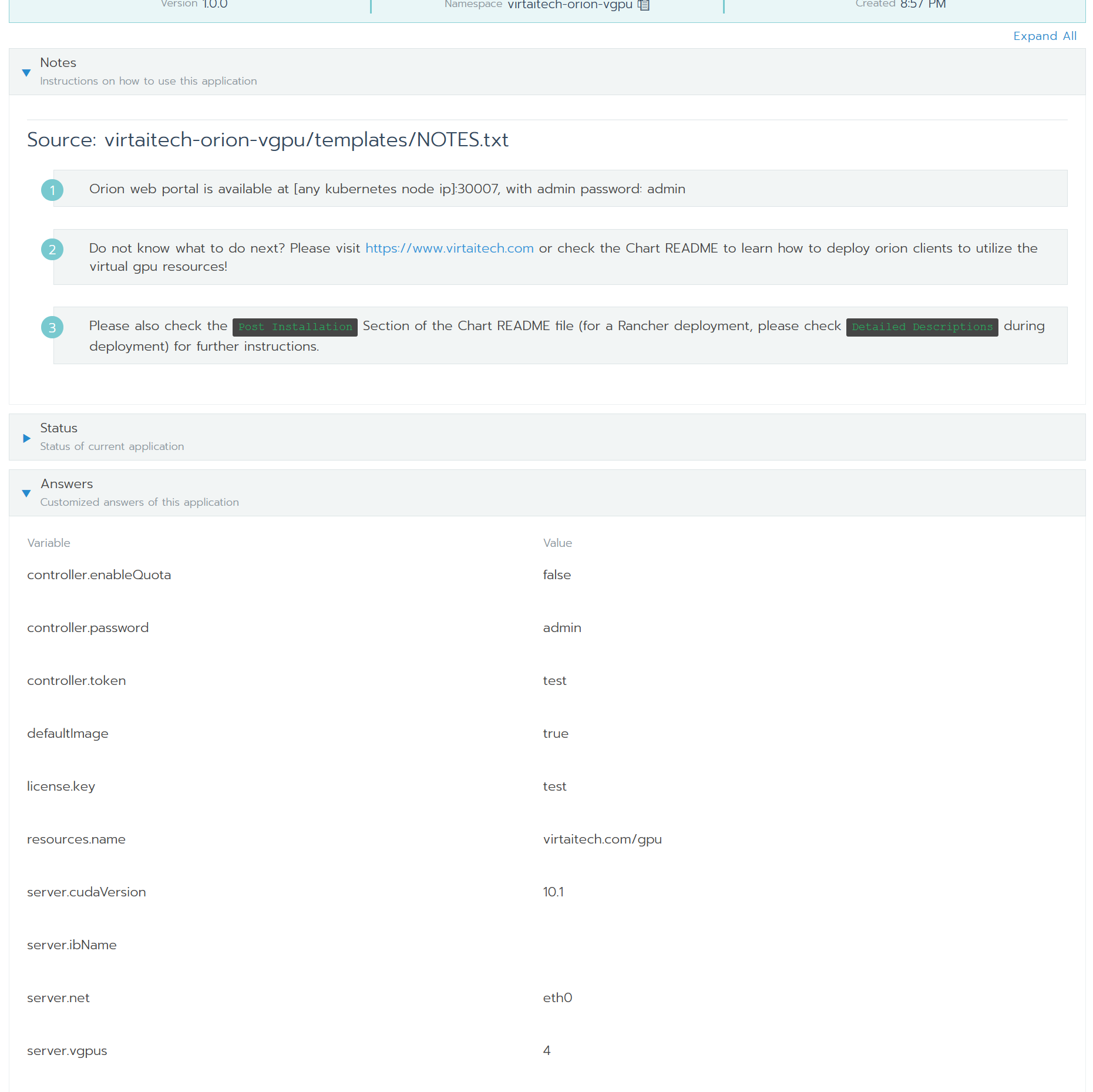
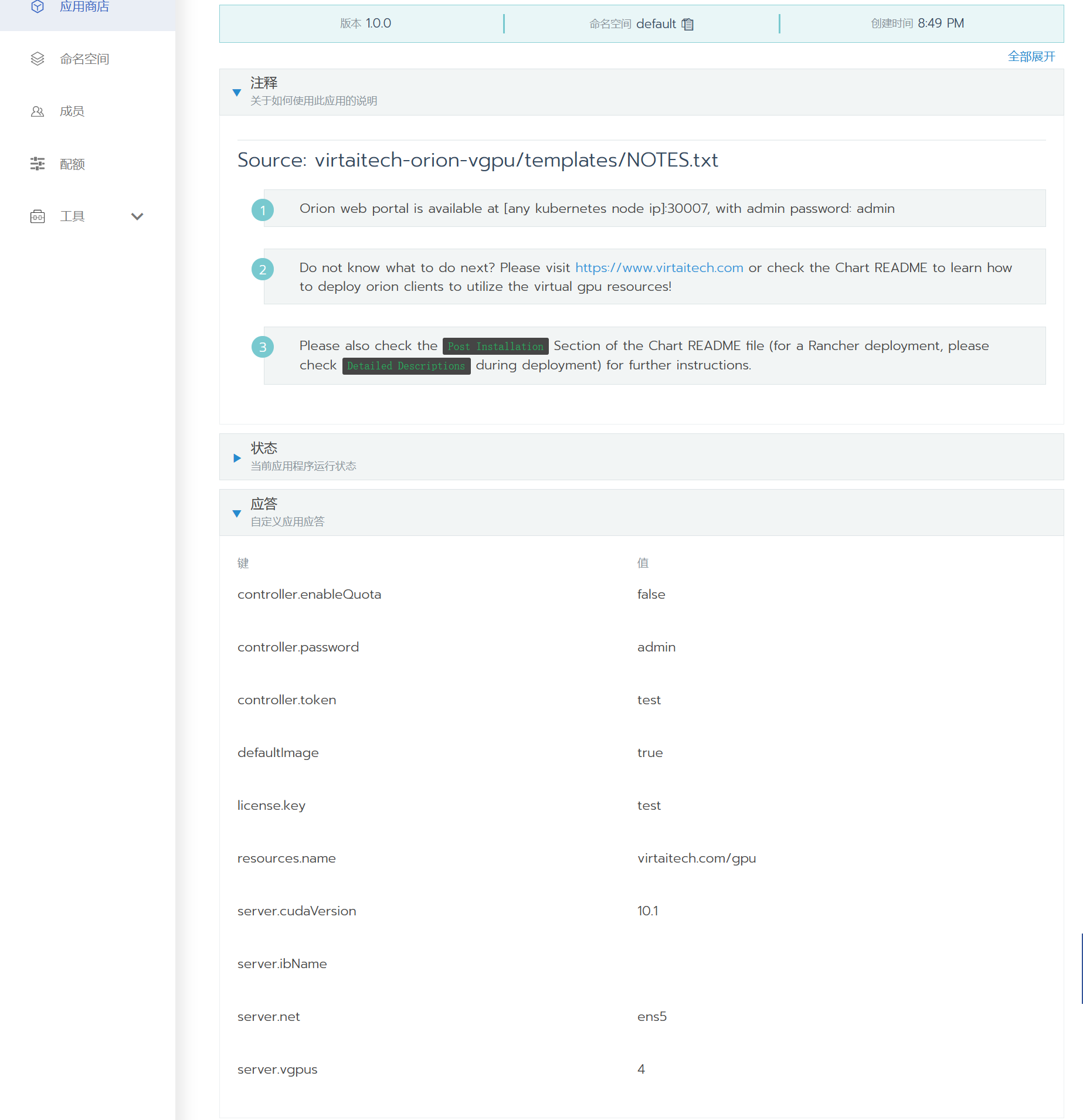
OrionX部署时使用的相关设置可以在部署后的应用界面查看。相关信息会显示在 Notes(或注释)和Answers(或应答)两栏下,如下图所示:
4. 配置详情
| 设置 | 说明 | 默认值 | 类型 |
|---|---|---|---|
| Name(名称) | Rancher App名称 | virtaitech-orion-vgpu | string |
| Template Version(模板版本) | Chart版本 | 1.0.0 | 下拉菜单 |
| Namespace(命名空间) | Kubernetes命名空间,可以新建或者选择现有命名空间 | 空 | string |
| Use Default Image | 使用默认镜像,通常不需要修改。如有必要,请在趋动科技工程师指导下修改这里的设置。 | True | bool |
| License Key | 新版license。直接作为字符串粘贴到这里即可。注意旧版的license无法使用。请联系趋动科技获取有效的license。获取license请参考:https://www.virtaitech.com/development/index#-12 | 空 | string |
| Controller Web Portal Password | 登录controller webui的密码(用户为admin)。controller的登录地址在应用部署完成界面的Notes一节可以查看。 |
空 | string |
| Controller Token | controller的token。调用controller高级api时需要给出这里设置的token。controller的高级api文档请详询趋动科技客户支持团队。 | 空 | string |
| Orion Resource Name | 暴露给Kubernetes的orion资源名称,客户端在申请orion资源时,需要使用这里设置的资源名称。通常不需要修改。特别和Rancher中国企业版整合时,修改这个名称将导致Rancher中国企业版无法正确启动Orion的客户端。 | virtaitech.com/gpu | string |
| Controller Quota | controller是否启用quota。 | false | bool |
| Server Cuda | server镜像内使用的cuda版本,可选值为"9.0","9.1","9.2","10.0","10.1"。 | 10.1 | string |
| Network Interface | (关键设置)Orion bind net的网卡名称。该设置会指定OrionX使用的网卡,特别当计算节点拥有多张网卡时,需要小心设置(例如,RDMA网卡和TCP网卡并存,最好指定RDMA网卡)。由于在Kubernetes环境下难以为每个节点独立配置orion server并指定bind address,需要为所有节点通过统一的网卡名称来配置Orion网络环境。这会引入一个前提:如果有节点配置使用的网卡名称必须相同,否则必须请IT、运维人员做相应修改。 | eth0 | string |
| VGPU Numbers | 每个物理GPU虚拟出几个VGPU。 | 4 | int |
| Infiniband Network Name | Infiniband网卡名称。非必填项。 | 空 | string |
5. 测试
Rancher中国企业版部署使用OrionX客户端
默认情况下,UI中不会启用Orion的支持参数,需要在启用一个特殊Feature。在“全局—系统设置 —功能选项”中,启用
virtaitech-gpu-service-ui,如图所示: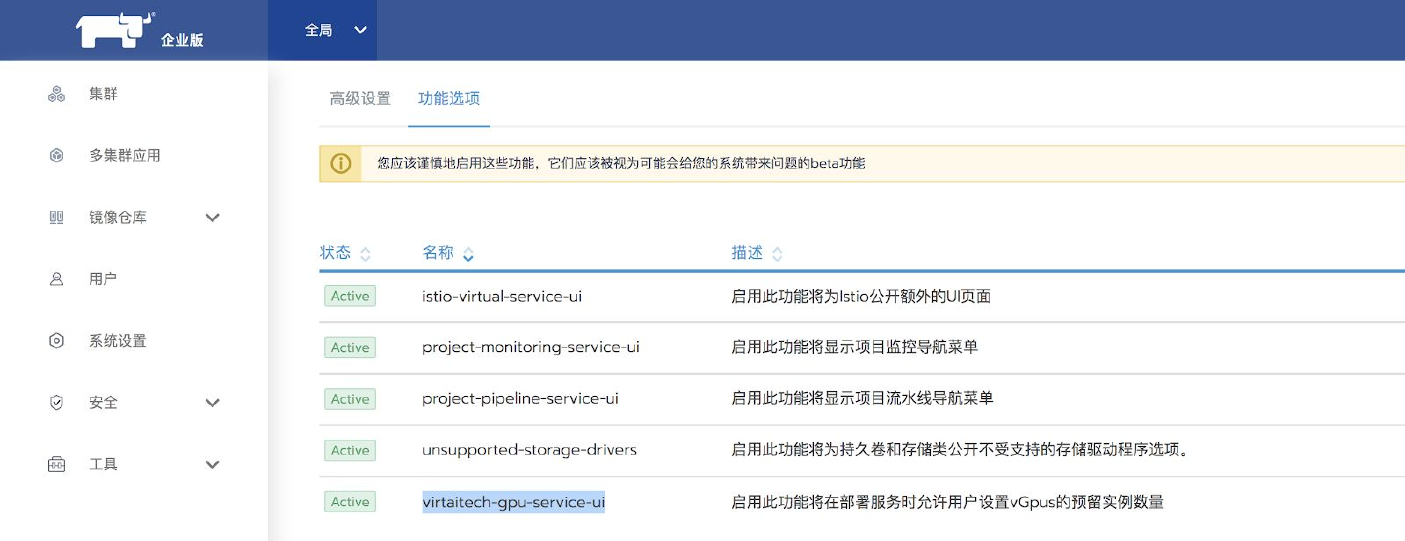
选择对应的集群和Project,选择
资源-工作负载,部署一个工作负载。配置客户端镜像,使用virtaitech/orion-client-2.2:cuda10.1-tf1.14-py3.6-hvd。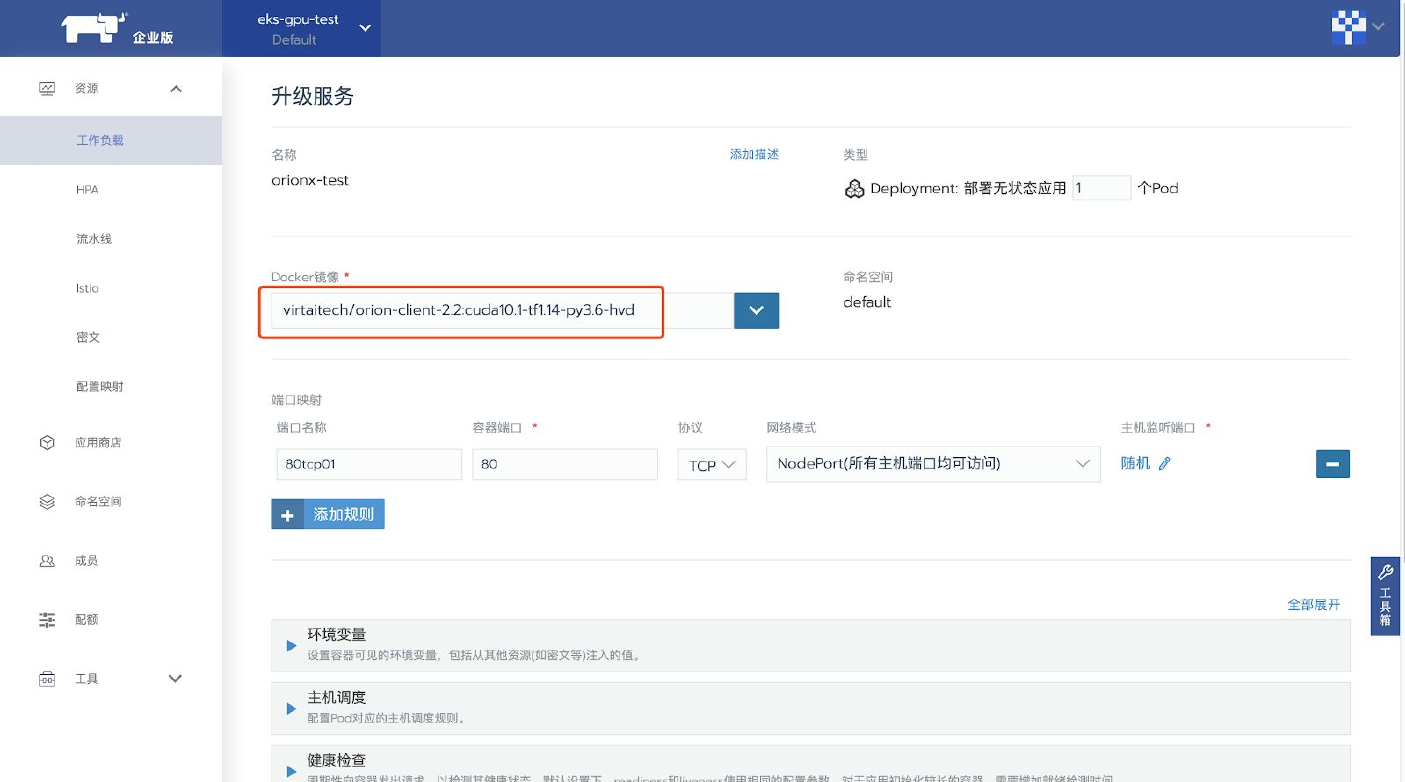
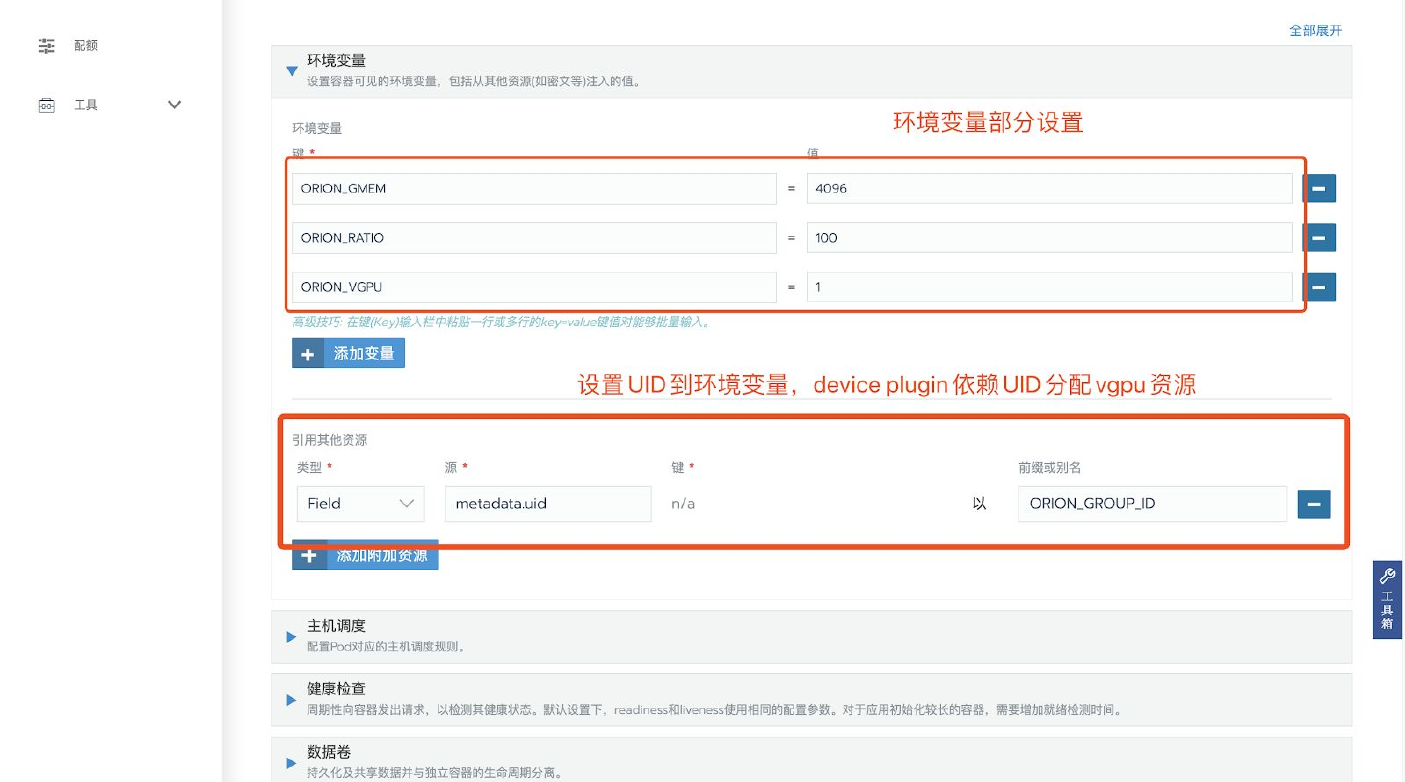
设置Orion资源环境变量,具体为(请根据实际需求配置):
env: - name: ORION_VGPU value: "1" - name: ORION_GMEM value: "4096" - name: ORION_RATIO value: "100" # whether the orion resources are revered or will be released after 30s idle. # If the value is not set, the resources are reserved by default. # Any value other than "1" will NOT reserve the resource. - name: ORION_RESERVED value: "0" - name: ORION_CROSS_NODE value: "0" - name : ORION_GROUP_ID valueFrom: fieldRef: fieldPath: metadata.uid各参数含义请参见下文Orion客户端启动配置说明。
配置使用
orion-scheduler调度器。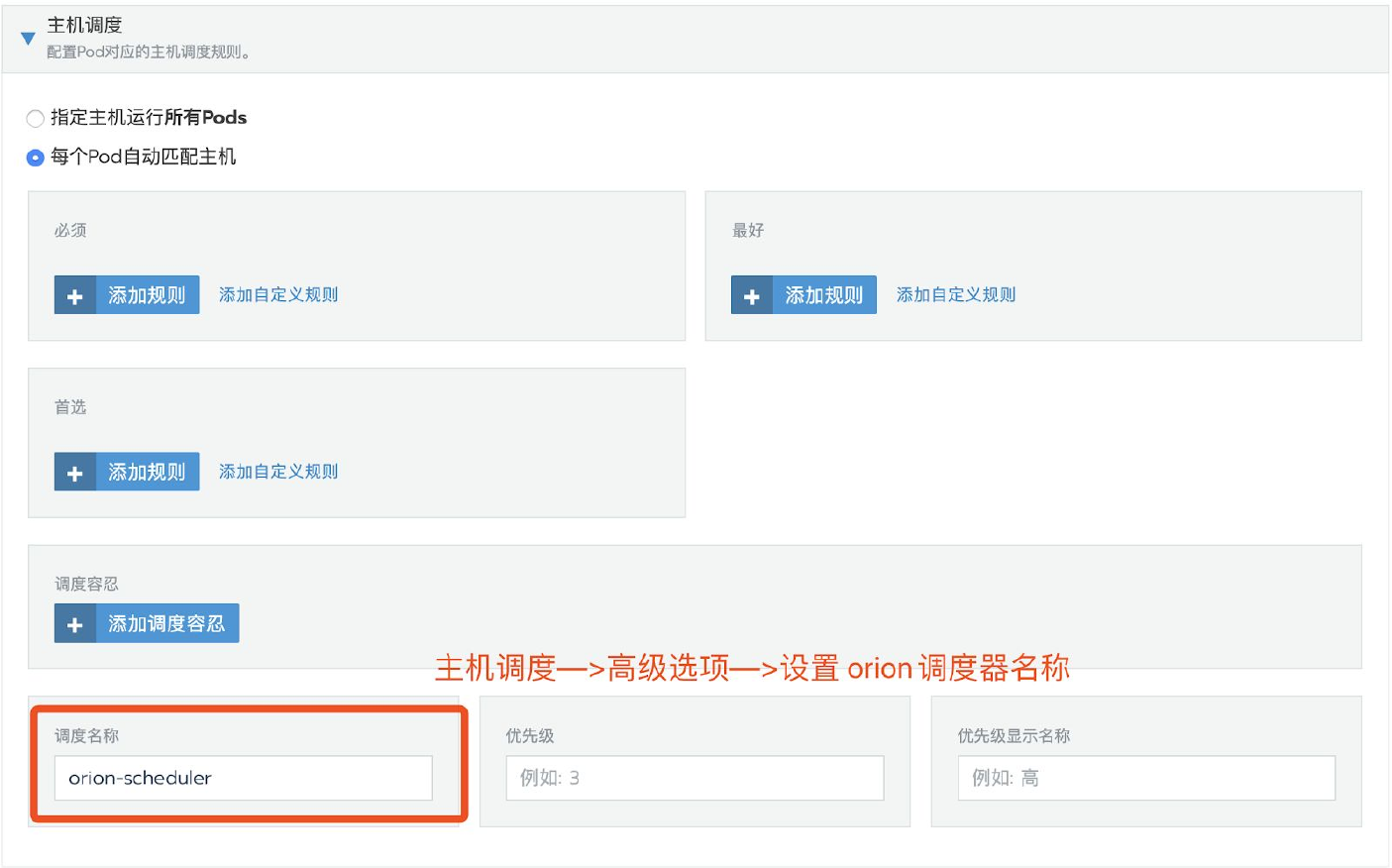
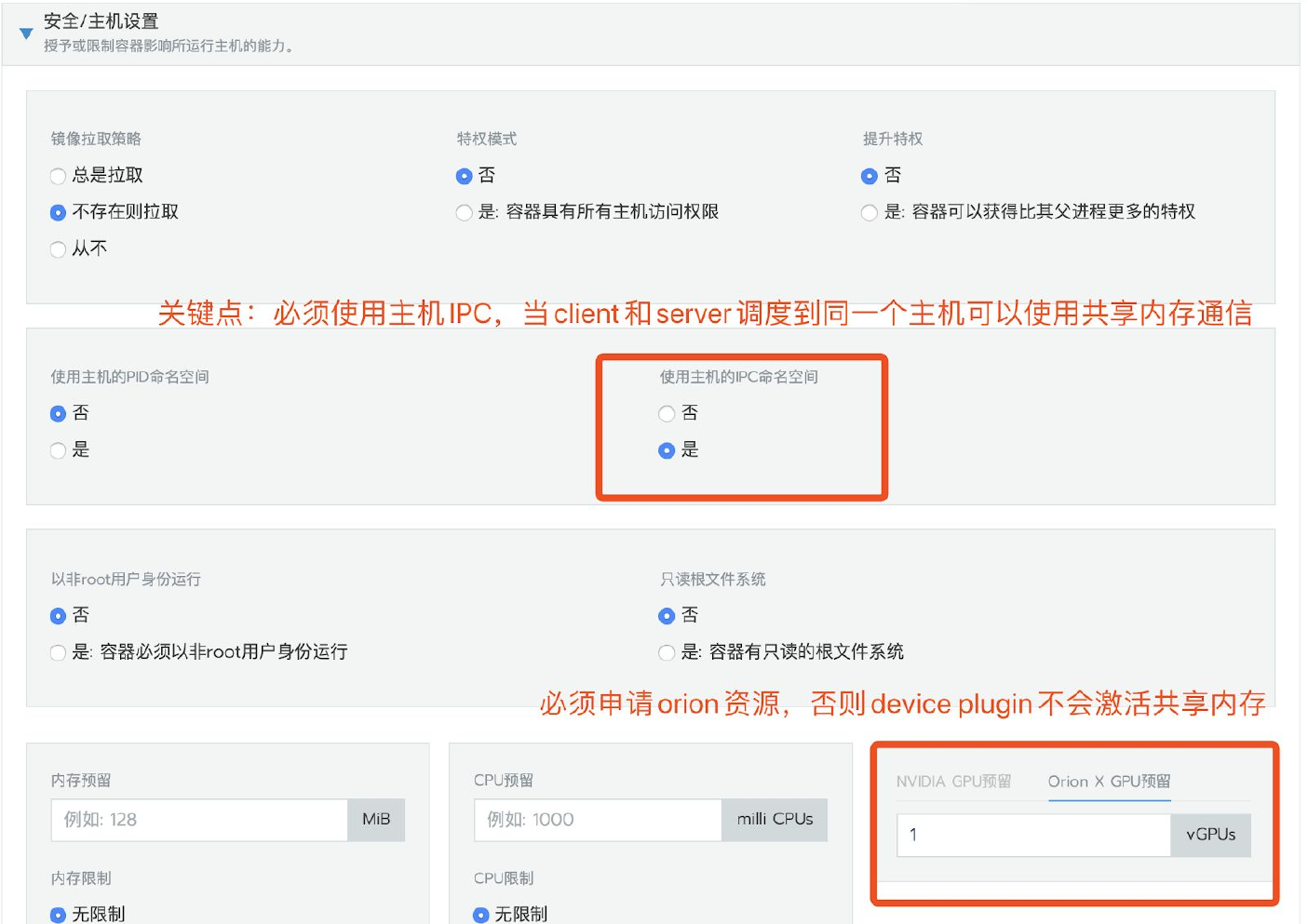
使用主机IPC命名空间,并申请OrionX GPU资源。
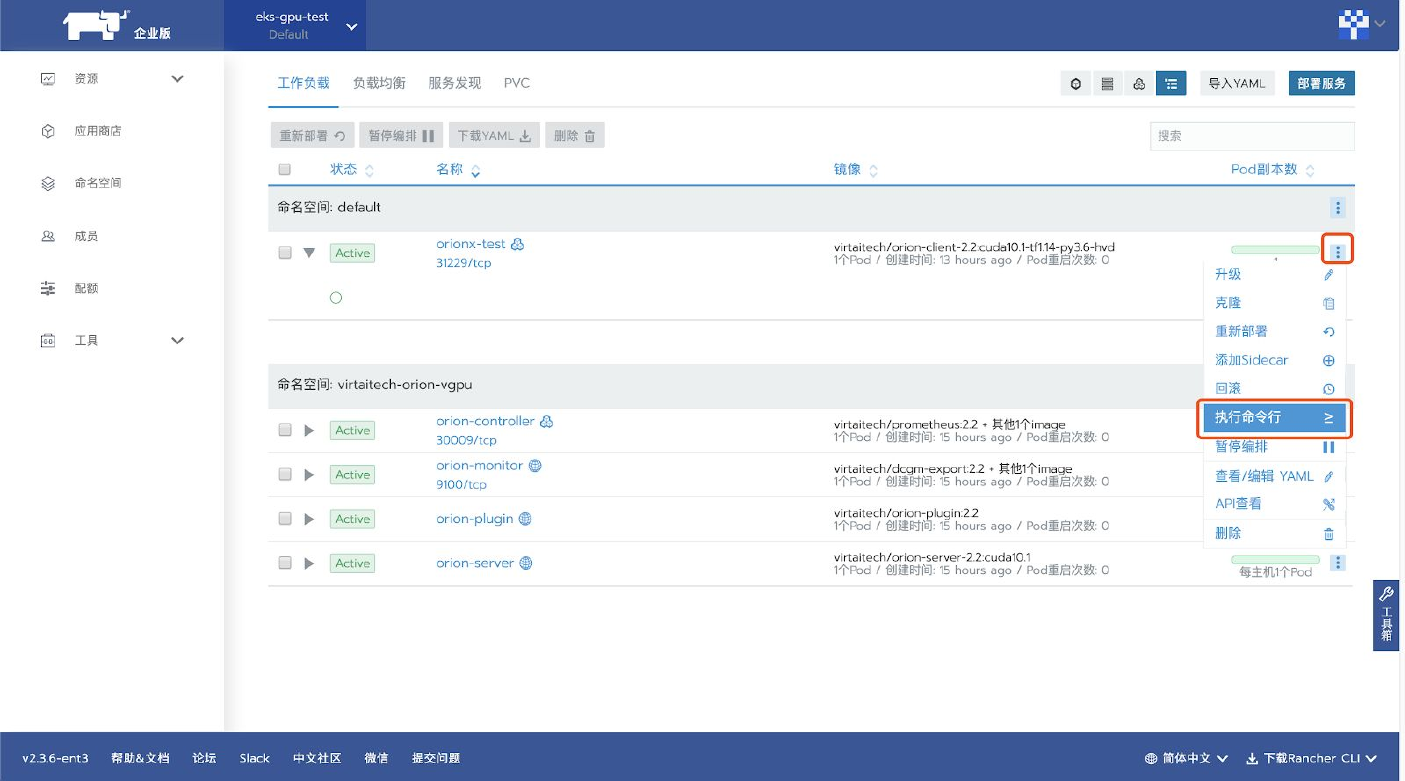
待客户端部署完成,可以在Rancher图形界面上进入客户端内执行命令。
例如可以执行:
/root/cuda_samples/deviceQuery/deviceQuery。客户端镜像内``/root/cuda_samples`路径下有大量的测试用例供客户使用。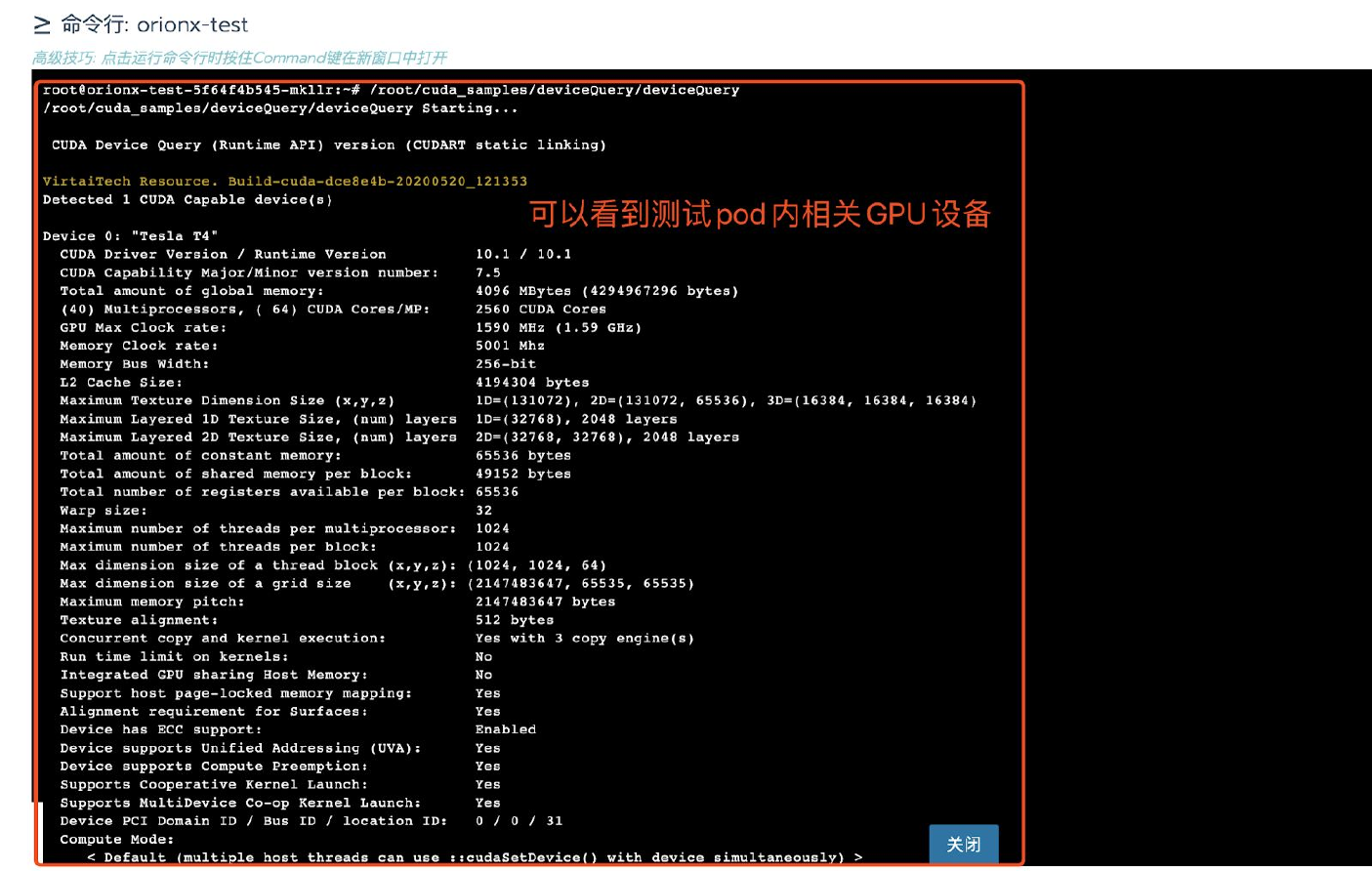
Rancher社区版使用OrionX
Rancher社区版缺少对OrionX客户端的一些整合支持。用户可以通过Kubernetes命令行工具部署OrionX的客户端。一个典型的测试yaml文件如下(各参数含义请参见下文Orion客户端启动配置说明):
# orion-client.yaml
apiVersion: v1
kind: Pod
metadata:
name: testgpu
spec:
schedulerName: orion-scheduler
hostIPC: true
containers:
- name: test
image: virtaitech/orion-client-2.2:cuda10.1-tf1.14-py3.6-hvd
command: ["sh", "-c", "sleep infinity"]
# Please make sure these values are properly set
env:
- name: ORION_VGPU
value: "1"
- name: ORION_GMEM
value: "4096"
- name: ORION_RATIO
value: "100"
# whether the orion resources are revered or will be released after 30s idle.
# If the value is not set, the resources are reserved by default.
# Any value other than "1" will NOT reserve the resource.
- name: ORION_RESERVED
value: "0"
- name: ORION_CROSS_NODE
value: "0"
- name : ORION_GROUP_ID
valueFrom:
fieldRef:
fieldPath: metadata.uid
resources:
limits:
# if you have changed Resource Name while deploying Orion services, please change this accordingly
virtaitech.com/gpu: 1
可以通过kubectl apply -f orion-client.yaml来部署客户端。客户端镜像内``/root/cuda_samples`路径下有大量的测试用例供客户使用。
Orion客户端启动配置说明
| 设置 | 说明 | 类型 |
|---|---|---|
spec.schedulerName |
使用的Kubernetes调度器的名称,请务必指定为orion-scheduler |
string |
spec.hostIPC |
请务必设置为true |
bool |
spec.containers[].env[].name="ORION_VGPU" |
申请的Orion VGPU个数,注意这里为字符串。该值请务必设置为与spec.containers[].resources.limits.virtaitech.com/gpu相同。字符串内容必须为正整数。 |
string |
spec.containers[].env[].name="ORION_GMEM" |
每个VGPU申请的显存,单位为兆(MB)。字符串内容必须为正整数。 | string |
spec.containers[].env[].name="ORION_RATIO" |
每个VGPU占用物理GPU算力的百分比。 | string |
spec.containers[].env[].name="ORION_GROUP_ID" |
必须按照示例设置。 | string |
spec.containers[].env[].name="ORION_RESERVED" |
OrionX的资源分配模式。当设置为1时,OrionX的资源分配与Kubernetes的pod的生命周期绑定。只要pod存在,则资源就会被保留,即使pod内没有在使用资源。这种模式下资源无法超发。当值设置为除1以外的其它值时,OrionX的资源只会(默认)预留30s。如果pod内没有在使用OrionX资源,则闲置30s后资源会被释放。这种该模式下资源可以超发。默认为1。 |
string |
spec.containers[].env[].name="ORION_CROSS_NODE" |
使用跨节点GPU,默认为0。 |
string |
spec.containers[].resources.limits.virtaitech.com/gpu |
必须为正整数(Kubernetes限制)。请将该值设置与spec.containers[].env[].name="ORION_VGPU"相同。 |
int |
进阶说明
- 当
ORION_RESERVED=1时,ORION_VGPU实际不生效(但需要设置),实际申请的VGPU资源数量基于spec.containers[].resources.limits.virtaitech.com/gpu。 - 当
ORION_RESERVED!=1时,pod调度时申请的资源基于spec.containers[].resources.limits.virtaitech.com/gpu。但如果资源闲置30s被释放后再次使用VGPU资源,则会依据ORION_VGPU(以及其它环境变量)的值申请资源。 - 当一个pod里面有多个container时,OrionX只会满足第一个设置了
spec.containers[].resources.limits.virtaitech.com/gpu的container资源申请要求。建议用户使用时只在一个pod里面让一个container申请OrionX资源。
使用示例
TensorFlow CNN Benchmark
在Orion客户端内执行:
# 注意ORION_RESERVED=1时,客户端内修改环境变量不生效
export ORION_VGPU=2
export ORION_GMEM=15000
export ORION_RATIO=100
python3 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py \
--model resnet50 \
--batch_size 64 \
--num_batches 40\
--num_gpus=2
使用跨节点GPU时可以使用horovod
export ORION_VGPU=4
export ORION_GMEM=15000
export ORION_RATIO=100
export ORION_CROSS_NODE=1
horovodrun -np 4 -H localhost:4 python3 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py \
--model resnet50 \
--batch_size 128 \
--num_batches 400 \
--variable_update horovod
Jupyter Notebook
# From inside Orion Client container
cd /root
pip3 install notebook
jupyter notebook --ip=0.0.0.0 --no-browser --allow-root
会看到类似于下面的输出:
# Omit output
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-38-open.html
Or copy and paste one of these URLs:
http://lab-0:8888/?token=4507dbe5c542dd570370c2425f14f83f06793da178978558
or http://127.0.0.1:8888/?token=4507dbe5c542dd570370c2425f14f83f06793da178978558
如果用户可以使用这台机器的图形界面,那么可以打开浏览器,输入所提示地址 127.0.0.1:8888/?token=<token>。
否则,用户可以在安装了浏览器的节点(例如笔记本电脑)上进行 SSH 端口转发:
# On laptop
ssh -Nf -L 8888:localhost:8888 <username@client-machine>
然后在本地浏览器里面输入 127.0.0.1:8888/?token=<token> 地址(将<token>替换成 Jupyter Notebook 所输出的实际 token)访问 Jupyter Notebook。
关于缺乏RDMA网络环境的说明
如果客户环境缺乏RDMA网络,需要手动开启TCP网络的支持(默认为关闭,以避免客户在具有RDMA网络环境下错误的使用TCP网络)。
kubectl exec -it pod/testgpu /bin/bash
vi /etc/orion/client.conf
[log]
log_with_time = true
log_to_screen = false
log_to_file = true
log_level = INFO
file_log_level = INFO
# add the following lines
[client]
enable_net = true
6. 常见问题
Orion Device Plugin
-
2020/05/21 06:58:33 Fail to get device list. Retry in 2 seconds ...
- 该问题通常是由
License Key设置错误导致。
- 该问题通常是由
-
2020/05/21 06:58:03 Waiting for network interface eth0
- OrionX要求所有节点上用于OrionX通信的网卡使用相同名称(例如
eth0)。用户务必确保这一前置条件满足,否则Orion Server在没有正确配置网卡名称的节点上无法正确启动。
- OrionX要求所有节点上用于OrionX通信的网卡使用相同名称(例如
-
Cannot reach orion contoller...
- 错误的
License Key会导致controller异常退出. 请与controller容器内部检查相应的日志,日志文件路径为/root/controller.log.
- 错误的
-
Orion Server
-
2020-05-21 07:02:33 [INFO] Waiting for net eth0 becoming ready ...
- OrionX要求所有节点上用于OrionX通信的网卡使用相同名称(例如
eth0)。用户务必确保这一前置条件满足,否则Orion Server在没有正确配置网卡名称的节点上无法正确启动。
- OrionX要求所有节点上用于OrionX通信的网卡使用相同名称(例如
-
Device "ens5" does not exist. Network interface ens5 dose not have a valid IPv4 address.
- 这里
ens5为Network Interface的配置。这条log说明Kubernetes集群中有一个节点没有ens5网卡,导致bind net失败。因此我们要求客户环境内节点使用统一的网卡命名,以便Orion使用。
- 这里
-
Orion Controller
/root/controller.log内只有一条日志:level=info msg="read license from license file"- 通常由于错误的license导致。请检查复制粘贴到rancher表单的license内容是否正确。
Orion Monitor
-
time="2020-05-21T06:58:03Z" level=info msg="Starting dcgm-exporter"
Error: Failed to initialize NVML
time="2020-05-21T06:58:03Z" level=fatal msg="Error starting nv-hostengine: DCGM initialization error"- 在非GPU节点上该错误为正常现象,可以忽略。
-
(已知问题)Rancher上部署的OrionX的GUI页面无法正确显示GPU利用率。
在Rancher k3s上快速开始使用OrionX
k3s是经CNCF一致性认证的Kubernetes发行版,专为物联网及边缘计算设计。OrionX可以非常方便的在k3s上部署使用。
环境准备
我们推荐客户使用Docker+NVidia Docker runtime环境来部署使用OrionX+k3s。用户需要
在所有节点上安装Docker。安装方法可以参考Docker官方文档。
在所有GPU节点上安装好GPU驱动(无需安装CUDA,OrionX不依赖原生CUDA)。
在所有GPU节点上安装NVidia Docker runtime,并设置为default runtime。可以参考下面的示例
安装nvidia-docker2:
# https://github.com/NVIDIA/k8s-device-plugin#preparing-your-gpu-nodes distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update && sudo apt-get install -y nvidia-docker2 sudo systemctl enable docker安装完nvidia-docker2后,我们要确保设置default runtime设置到nvidia:
# /etc/docker/daemon.json { "default-runtime": "nvidia", "runtimes": { "nvidia": { "path": "/usr/bin/nvidia-container-runtime", "runtimeArgs": [] } } } sudo systemctl restart docker如果使用公有云,可以在申请GPU实例时使用配置好GPU驱动+CUDA+Docker+NVidia Docker runtime的镜像。
具体可以参考k3s中文社区文档:如何在k3s环境中安装GPU相关程序 。
快速安装Rancher k3s
准备好节点环境,即可方便快速的部署k3s。
# 在控制面(server)节点执行如下指令:
curl -sfL https://get.k3s.io | INSTALL_K3S_EXEC="--docker" sh -s -
# 国内用户,可以使用以下方法加速安装:
curl -sfL https://docs.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn INSTALL_K3S_EXEC="--docker" sh -s -
# 在worker(agent)节点执行如下命令,其中:
# K3S_URL是可以访问的控制面板节点地址
# K3S_TOKEN保存在控制面(server)节点的/var/lib/rancher/k3s/server/node-token路径下。
curl -sfL https://get.k3s.io | INSTALL_K3S_EXEC="--docker" K3S_URL=https://myserver:6443 K3S_TOKEN=mynodetoken sh -
# 国内用户,可以使用以下方法加速安装:
curl -sfL https://docs.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn INSTALL_K3S_EXEC="--docker" K3S_URL=https://myserver:6443 K3S_TOKEN=mynodetoken sh -
具体可以参考k3s官方文档。
如果需要使用kubectl访问控制k3s集群,需要进行一些简单的配置:
- 方法一:设置
KUBECONFIG环境变量:
export KUBECONFIG=/etc/rancher/k3s/k3s.yaml
kubectl get pods --all-namespaces
- 方法二:指定
--kubeconfig参数:
kubectl --kubeconfig /etc/rancher/k3s/k3s.yaml get pods --all-namespaces
- 方法三:将
/etc/rancher/k3s/k3s.yaml拷贝到~/.kube/config。
具体可以参考k3s官方文档。
k3s上使用OrionX
有多种方式可以让用户在k3s上方便快速地部署使用OrionX。下面一一介绍。
Rancher+k3s+OrionX
k3s作为Rancher旗下一个轻量级的Kubernetes发行版本,与Rancher具有极佳的兼容性,可以方便地使用Rancher进行管理。
首先需要在Rancher上导入k3s集群,下图以Rancher企业版为例,Rancher社区版操作类似:
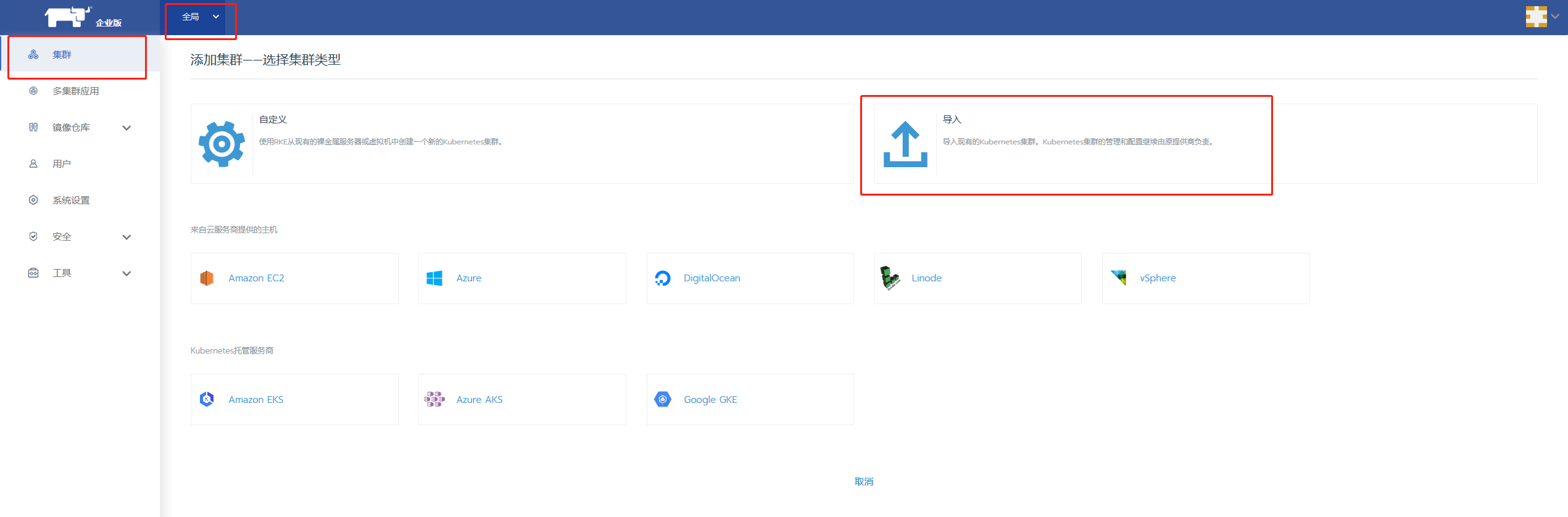
随后既可以参考文档**OrionX-Rancher集成指南**方便地使用Rancher部署使用OrionX了。
k3s在某些情况下会导致hostNetwork: true的pod无法访问到ClusterIP服务。如果遇到该情况,请参考helm+OrionX一节。
helm+OrionX
OrionX支持使用helm工具在k3s上进行快速部署。请参考文档**使用Helm部署OrionX**。
k3s在某些情况下会导致hostNetwork: true的pod无法访问到ClusterIP服务。如果遇到该情况,请使用特殊的chart分支:
git clone https://github.com/wpfnihao/pandaria-catalog.git -b dev/k3s
并在values.yaml文件中正确设置k3s相关内容。例子:
k3s:
enabled: true
# Interesting Config:
# Please make sure this value is set to any accessible k3s node ip
hostIP: "127.0.0.1"
k3s helm CRD+OrionX
k3s默认支持通过helm CRD来部署helm chart(参考:https://rancher.com/docs/k3s/latest/en/helm/)。
用户需要准备k3s helm CRD支持的yaml文件,如下所示。可以看到,所有设置项均与**使用Helm部署OrionX**相同。用户通过下方示例创建yaml文件(例如orion.yaml)并对设置项进行相应修改后,可以将该文件拷贝至k3s server节点/var/lib/rancher/k3s/server/manifests目录下。k3s helm CRD控制器会自动根据设置内容拉起所有Orion组件。
apiVersion: helm.cattle.io/v1
kind: HelmChart
metadata:
name: virtaitech-orion-vgpu
namespace: kube-system
spec:
chart: virtaitech-orion-vgpu
repo: https://wpfnihao.github.io/pandaria-catalog
targetNamespace: virtaitech-orion-vgpu
valuesContent: |-
image:
pullPolicy: IfNotPresent
imagePullSecrets:
resources:
# Interesting Config:
# resource name exposed by Orion
name: "virtaitech.com/gpu"
monitor:
collectorPath: /run/prometheus
image:
exporter:
# nvidia/dcgm-exporter
repository: virtaitech/dcgm-export
version: "2.2"
prometheus:
# quay.io/prometheus/node-exporter
repository: virtaitech/node-exporter
version: "2.2"
# this port is also used by controller to scrap info.
# should not change this value
port: 9100
controller:
version: "2.2"
name: "orion-controller"
port: "15500"
portName0: "controller"
portName1: "port1"
portName2: "webportal"
nodeport: 30007
service: orion-controller
image:
prom: virtaitech/prometheus
repository: virtaitech/orion-controller
version: "2.2"
# Interesting Config:
password: ""
# Interesting Config:
# or true
enableQuota: false
# Interesting Config:
token: ""
# changing this value not tested
replicas: 1
helper:
image:
repository: virtaitech/orion-helper
version: "2.2"
server:
port: "9960"
# Interesting Config:
# TODO: requires additional images
cudaVersion: "10.1"
image:
version: "2.2"
path:
comm: /var/tmp/orion/comm
# Interesting Config:
net: ens5
# Interesting Config:
vgpus: 4
# Interesting Config:
ibName: ""
plugin:
path: /var/lib/kubelet/device-plugins
image:
repository: virtaitech/orion-plugin
version: "2.2"
scheduler:
replicas: 1
apiVersion: "2.2"
dataVersion: "2.2"
image:
scheduler:
# gcr.io/google_containers/hyperkube:v1.16.3
repository: virtaitech/hyperkube
version: "2.2"
extender:
repository: virtaitech/k8s-scheduler-extender
version: "2.2"
port: 8888
verbose: 4
license:
# Interesting Config:
key: ""
volumes:
shm: /dev/shm
几点说明:
- 特别适合通过本方式将Orion作为k3s的常驻组件进行部署。
- 修改
/var/lib/rancher/k3s/server/manifests/orion.yaml文件会更新CRD控制器,但执行逻辑与helm upgrade不同。 - 删除
orion.yaml文件不会卸载已部署的Orion组件(与helm uninstall逻辑不同)。 - k3s在某些情况下会导致
hostNetwork: true的pod无法访问到ClusterIP服务。如果遇到该情况,请参考helm+OrionX一节。
使用Helm部署OrionX
本文介绍使用Helm命令行工具将OrionX所有组件部署到Kubernetes环境。
Orion已经与企业级Kubernetes管理平台Rancher深度整合,你可以通过Rancher中国应用商店直接部署Orion。具体请参考Rancher应用商店以及OrionX-Rancher集成指南。
获取官方Orion Helm Chart
使用如下指令获取官方Orion Helm Chart:
git clone https://github.com/cnrancher/pandaria-catalog.git -b dev/v2.3
安装部署
在可以通过kubectl访问Kubernetes的节点上安装Helm工具。
# 1.1 测试kubectl可以正常工作 kubectl get nodes # 示例输出 #NAME STATUS ROLES AGE VERSION #ip-172-31-28-1 Ready worker 24d v1.17.5 #ip-172-31-43-188 Ready worker 24d v1.17.5 #ip-172-31-43-87 Ready controlplane,etcd 24d v1.17.5 # 1.2 安装helm # Ubuntu上可以直接通过snap安装 # 其它包管理器下安装helm请参考 # https://helm.sh/docs/intro/install/ # 或者 # https://github.com/helm/helm/releases sudo snap install helm --classic # 测试helm可以正常与Kubernetes通信 helm list # 示例输出 #NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION修改安装配置
所有配置信息都通过修改
pandaria-catalog/charts/virtaitech-orion-vgpu/v1.0.0/values.yaml实现(其它chart配置方式请参考Helm官方文档)大部分配置均不需要修改,少数需要修改的配置均通过注释
# Interesting Config:标出。关键配置的说明如下:设置 说明 默认值 类型 resources.name 暴露给Kubernetes的orion资源名称,客户端在申请orion资源时,需要使用这里设置的资源名称。通常不需要修改。特别和Rancher整合时,修改这个名称将导致Rancher无法正确启动Orion的客户端(Rancher固定使用virtaitech.com/gpu作为Orion资源名) virtaitech.com/gpu string controller.password 登录controller webui的密码(用户为admin)。controller的登录地址在使用 helm install部署时将通过stdout输出,请注意查看。空 string controller.enableQuota controller是否启用quota。 false bool controller.token controller的token。调用controller高级api时需要给出这里设置的token才能调用成功。 空 string server.cudaVersion server镜像内使用的cuda版本,可选值为"9.0","9.1","9.2","10.0","10.1"。 10.1 string server.net (关键设置)Orion bind net的网卡名称。该设置会指定OrionX使用的网卡,特别当计算节点拥有多张网卡时,需要小心设置(例如,RDMA网卡和TCP网卡并存,最好指定RDMA网卡)。由于在Kubernetes环境下难以为每个节点独立配置orion server并指定bind address,需要为所有节点通过统一的网卡名称来配置Orion网络环境。这会引入一个前提:如果有节点配置使用的网卡名称必须相同,否则必须请IT、运维人员做相应修改。 eth0 string server.vgpus 每个PGPU虚拟出几个VGPU 4 int server.ibName Infiniband网卡名称。非必填项。 空 string license.key 新版license。直接作为字符串粘贴到这里即可。注意旧版的license无法使用。请联系趋动科技获取有效的license。获取license请参考:https://www.virtaitech.com/development/index#-12 空 string scheduler.apiVersion controller使用的api版本。scheduler与controller通信时会使用。通常与controller的版本相同。 2.2 string scheduler.dataVersion 同上。 2.2 string
相关说明
自定义镜像
通常每个组件使用的image可以通过组件下的
image.repository和image.version来设置。例如:helper: image: repository: virtaitech/orion-helper version: "2.2"则最终orion helper使用的image为:
virtaitech/orion-helper:2.2但是orion server的情况比较特殊,请参考下文说明。
orion helper说明
Orion部署完成后请通过
kubectl describe node <nodeName>查看每个node的label,确保ORION_BIND_ADDR=<ip_address>已经通过orion helper正确设置。如果没有的话,需要手动添加label:kubectl label nodes <nodeName> ORION_BIND_ADDR=<ip_address>。这里<ip_address>需要和server.net处设置的网卡的ip地址相同。如果orion server在对应节点上启动失败,则orion helper也无法正确打label。orion server镜像说明
orion server具体使用的镜像通过
server.image.version和server.cudaVersion的组合指定。如果使用其它镜像,请将image tag成表格中的格式,并设置这两个值。请注意现在DockerHub上只有2.2+10.1的镜像(virtaitech/orion-server-2.2:cuda10.1),如果需要使用其它版本,请使用趋动工程师提供的镜像包,并通过docker load导入镜像到每一个节点的docker daemon并打好相应tag,例如virtaitech/orion-server-2.2:cuda9.1。或者把镜像push到私有registry上。如果私有registry有访问控制,需要设置values.yaml中imagePullSecrets的值。
安装部署
配置好
values.yaml文件后,就可以通过helm安装所有Orion组件# helm可以一键部署orion helm install pandaria-catalog/charts/virtaitech-orion-vgpu/v1.0.0/ --generate-name # 如果想要看到helm生成的所有yaml文件,可以使用debug参数 helm install pandaria-catalog/charts/virtaitech-orion-vgpu/v1.0.0/ --generate-name --debug部署完成后可以使用
helm list查看部署状态。示例输出为:NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION orion-gpu-1591596688 default 1 2020-06-08 06:11:28.953306413 +0000 UTC deployed virtaitech-orion-vgpu-1.0.0 2.2部署完成后可以通过
kubectl get all查看部署的Orion组件状态,示例输出为:NAME READY STATUS RESTARTS AGE pod/orion-controller-5bd9578d87-4dm5n 2/2 Running 0 5m49s pod/orion-monitor-qxftd 2/2 Running 0 5m49s pod/orion-monitor-s2rjl 2/2 Running 0 5m49s pod/orion-plugin-lwbfk 1/1 Running 0 5m49s pod/orion-plugin-n2jvc 1/1 Running 0 5m49s pod/orion-server-4c6tx 1/1 Running 0 5m49s pod/orion-server-dtltp 0/1 CrashLoopBackOff 5 5m49s pod/orion-helper-49xzz 1/1 Running 0 12m pod/orion-helper-vk2z9 1/1 Running 0 12m pod/orion-scheduler-5c7f495cf-92bpp 2/2 Running 0 12m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/kubernetes ClusterIP 10.43.0.1 <none> 443/TCP 26d service/orion-controller ClusterIP 10.43.173.242 <none> 15500/TCP,15501/TCP,15502/TCP 5m49s service/orion-controller-nodeport NodePort 10.43.44.103 <none> 15502:30009/TCP 5m49s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/orion-monitor 2 2 2 2 2 <none> 5m49s daemonset.apps/orion-plugin 2 2 2 2 2 <none> 5m49s daemonset.apps/orion-server 2 2 1 2 1 <none> 5m49s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/orion-controller 1/1 1 1 5m49s NAME DESIRED CURRENT READY AGE replicaset.apps/orion-controller-5bd9578d87 1 1 1 5m49s注意这里有一个
orion-server没有能正常启动。通过kubectl logs pod/orion-server-dtltp查看日志,示例输出为:Device "ens5" does not exist. Network interface ens5 dose not have a valid IPv4 address.这里
ens5为server.net的配置。这条log说明Kubernetes集群中有一个节点没有ens5网卡,导致bind net失败。因此我们要求客户环境内节点使用统一的网卡命名,以便Orion使用。
使用
Orion客户端的使用方式可以参考OrionX-Rancher集成指南中
测试一节。如果想要清理所有Orion的组件,可以使用
helm list输出的NAME进行卸载:helm uninstall orion-gpu-1591596688


